
Introduction
This is a series of blog posts related to alternatives to Reinforcement Learning by Human Feedback, created as a joint effort between Argilla and MantisNLP teams. Please ensure you have gone through the previous entries in the series to fully understand the context and progression of the discussion before moving on to this segment. Scroll to the bottom of the page to go to the next blog post of the series.
In previous posts, we started by analyzing the efforts to carry out Supervised Fine-tuning (SFT) and Reinforcement Learning with Human Feedback (RLHF), and the importance of having high-quality data (first and second blog posts). Nevertheless, RLHF is complex and usually unstable, so we examined a promising alternative, Direct Preference Optimization (DPO), to align the LLM with human preferences without requiring RL (third blog post). Still, DPO does not solve all the shortcomings, for instance, a large amount of preference data is needed to fine-tune. To tackle this, researchers have come up with new methods. Some of them are Reinforcement Learning AI Feedback (RLAIF) or Self-Play Fine-Tuning (SPIN) (fourth and fifth blog posts). For better data alignment, we also explored the benefits of Identity Preference Optimization (IPO) and Kahneman-Tversky Optimization (KTO) (sixth and seventh blog posts). ORPO was also described as it simplified the alignment process (eight blog post). In the ninth blog post, we discussed in an overview the advantages and disadvantages of the methods presented so far. The last post talked about DOVE, an objective for preference optimization that aims to align language models by learning from preferences over pairs of instructions and responses.
In this new post, we discuss SimPO, which stands for Simple Preference Optimization, introduced by Meng et al. (2024). This approach serves as an alternative to Reinforcement Learning with Human Feedback and Direct Preference Optimization, which we introduced in the third blog post. This new method aims to align the reward and generative models, making it appear more intuitively correct. In other words, a method to better align our preferences, a certain state of the world, and the LLM behavior.
DPO: Align model with human preferences but misalignment with the model metrics
Generally, once we have applied the supervised fine-tuning step (SFT) to the Large Language Model, we want to align this generative model with human preferences. In most of the alignment methods, such as Direct Preference Optimization, DPO, the most well-known, we design a reward model. However, this reward model does not necessarily take into account the metric that guides the generation model.
Let’s start by defining the reward model and the generative model in the easiest way possible, without complex math. The reward model is a function
Now, let’s define our generative model as
In other words, the likelihood of generating
Theoretically, when discussing the alignment of a Large Language Model with human preferences, we aim to align the reward model
We measure this equivalence with the reward accuracy. The higher the metric, the better alignment we have between our preferences and the generative capabilities of the LLM. For instance, on the UltraFeedBack dataset, a diverse preference dataset, the Mistral-8B-Base model’s reward accuracy reaches 52% on the training set when trained with DPO. This highlights the divergence between this reward model and the generation objective, as almost half of the preferences are not reflected in the likelihood of the generative model.
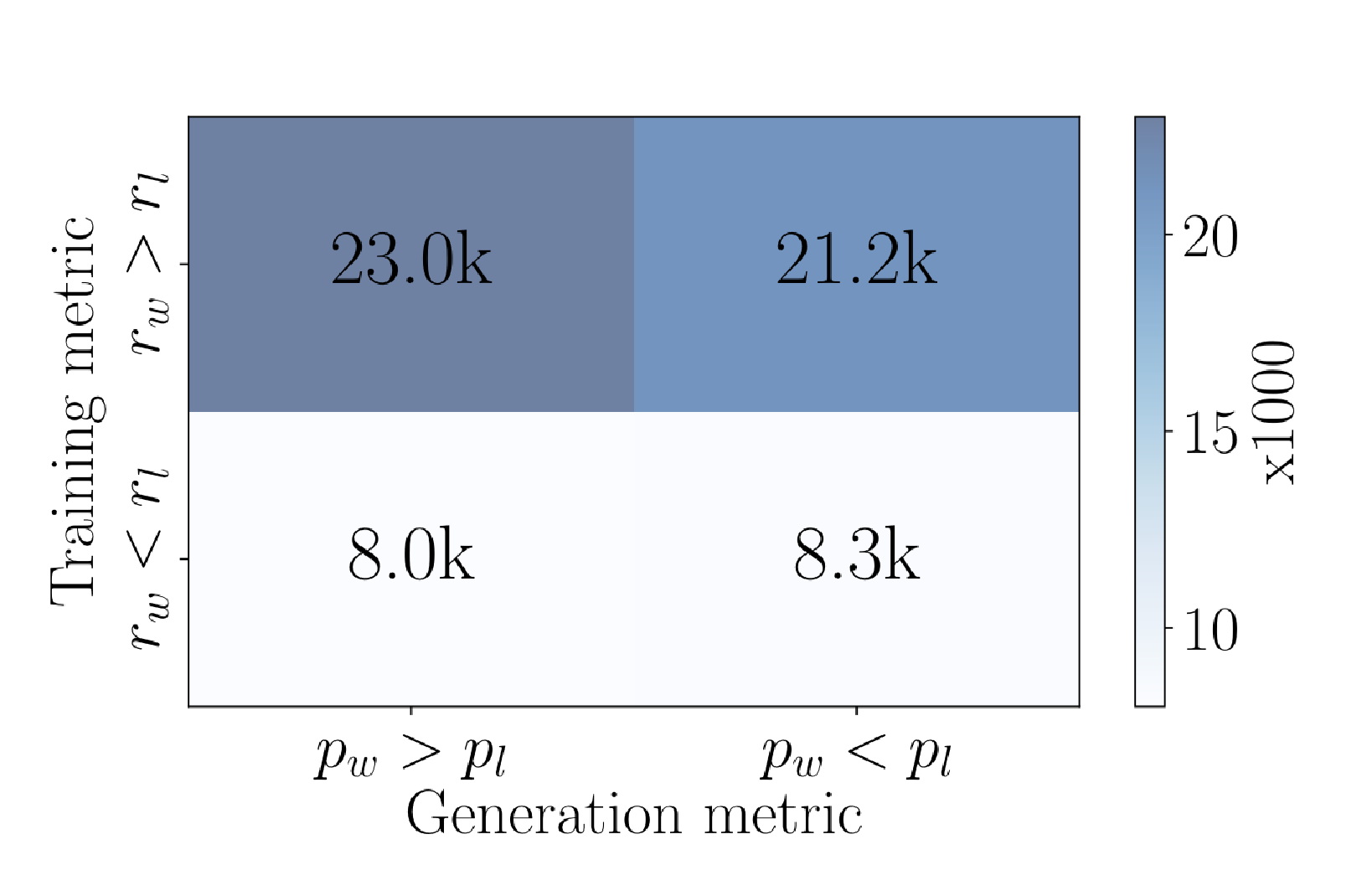 Contingency table for the Mistral-Base model on the UltraFeedBack training dataset. https://arxiv.org/pdf/2405.14734
Contingency table for the Mistral-Base model on the UltraFeedBack training dataset. https://arxiv.org/pdf/2405.14734
SimPO vs DPO: Looking for better alignment and faster computing
Let's dive a bit deeper into the formalism of DPO’s reward and generative models and highlight the differences implemented in SimPO that led to better reward accuracy and other downstream benefits.
Generative Model: identical for DPO and SimPO
First, let’s look formally at the generative model, which, in the end, is the model users play with on a daily basis behind chatGPT, Mixtral or Llama. The generative model includes a policy
DPO Background: reward model
The DPO paper defines the final reward model as:
Where
As we saw in the previous section, this DPO approach leads to misalignment between the generative models used during inference and the reward model. Additionally, it uses two policies
SimPO reward model: Simpler policy
To overcome those problems, the authors decided to adopt a simpler reward function:
Actually, they directly use the likelihood metric that guides generation in the reward model. This straightforward formulation theoretically has two advantages compared to the previous reward function: first the reward is directly proportional to the metric used to guide generation. Second it eliminates the need for a reference model, leading to greater compute and memory efficiency.
The last difference the authors of SimPO introduced addresses the Bradley-Terry objective. This is the function we optimize during the alignment process, ensuring that the outputs are generated according to our preferences. They added a target reward margin in the objective. Mathematically, the objective is designed as follows:
In DPO, the margin
Improvements of SimPO: Better alignment, Faster computing, Make it more robust
Now, let’s concretely highlight whether the simpler policy definition and target margin lead to the desired outcomes. We will obviously look at the general results of models trained with SimPO instead of DPO on well-known benchmarks.Nevertheless, first, we want to verify if the hypotheses made in the reward model design result in the expected improvements.
Increased reward accuracy and lower memory
We mentioned the two main expected contributions of the SimPO reward model: improving the alignment between the reward model and the likelihood of the generative model, and making the training faster and more efficient. The results provided in the paper are quite straightforward:
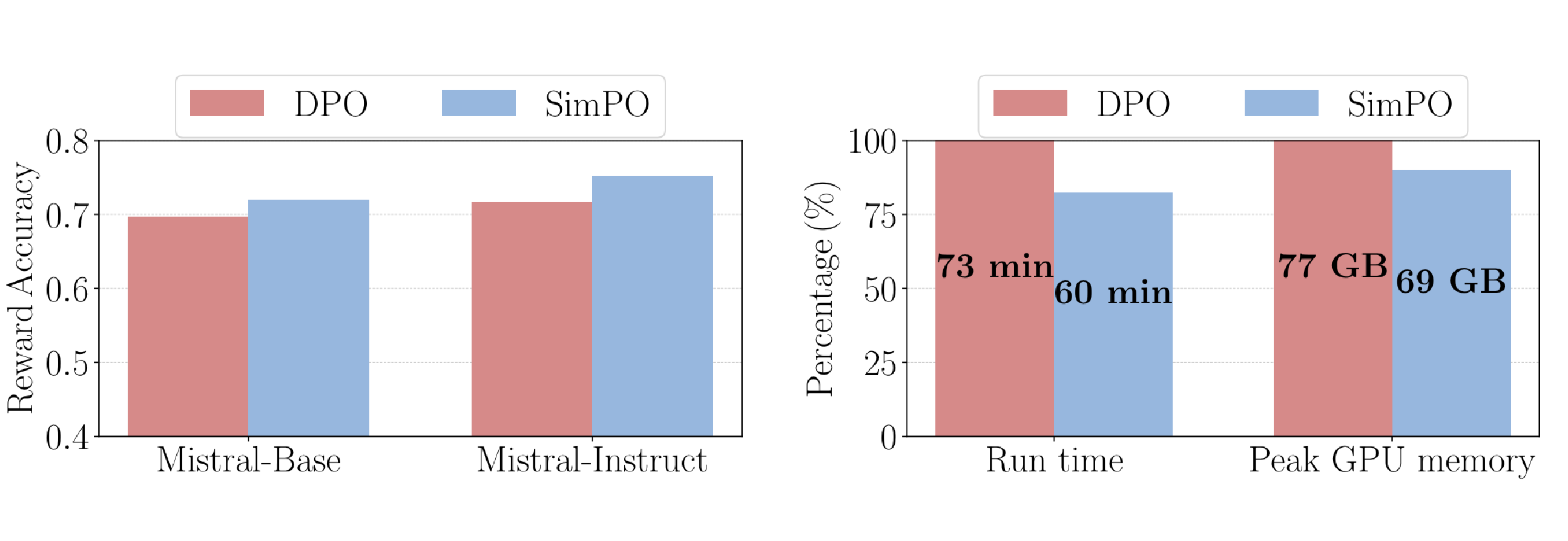 Reward accuracy and computation metrics for the Mistral-Base and Mistral-Instruct models. https://arxiv.org/pdf/2405.14734
Reward accuracy and computation metrics for the Mistral-Base and Mistral-Instruct models. https://arxiv.org/pdf/2405.14734
The authors tested it with two different open-source models: Llama 3-8B and Mistral-8B, considering both the Base model and the Instruct model in each case. They reported metrics for the Mistral models when trained with both the DPO reward modeling and SimPO’s reward. An increase in reward accuracy was observed for both Mistral-Base and Mistral-Instruct, which means better alignment between the generation model and the reward model.
Moreover, the authors study the effect of the margin
Regarding computation, we already mentioned that SimPO does not require a reference model. It leads to reduced overall run time and per-GPU peak memory usage. In the Llama3-Base setting SimPO reduces run time by approximately 20% and GPU memory usage by around 10% compared to the standard DPO implementation. By eliminating the need for forward passes with the reference model, the authors have clearly improved performance.
In conclusion, it appears that the changes in the reward modeling function have clearly met expectations, improving performance in terms of computational efficiency and better alignment with the metric that guides text generation.
Improved data length robustness
Another interesting result presented in this paper is the effect of the length normalization on the generated output. We did not mention it in the SimPO reward model. Let’s recap the SimPO reward model:
We notice the explicit usage of
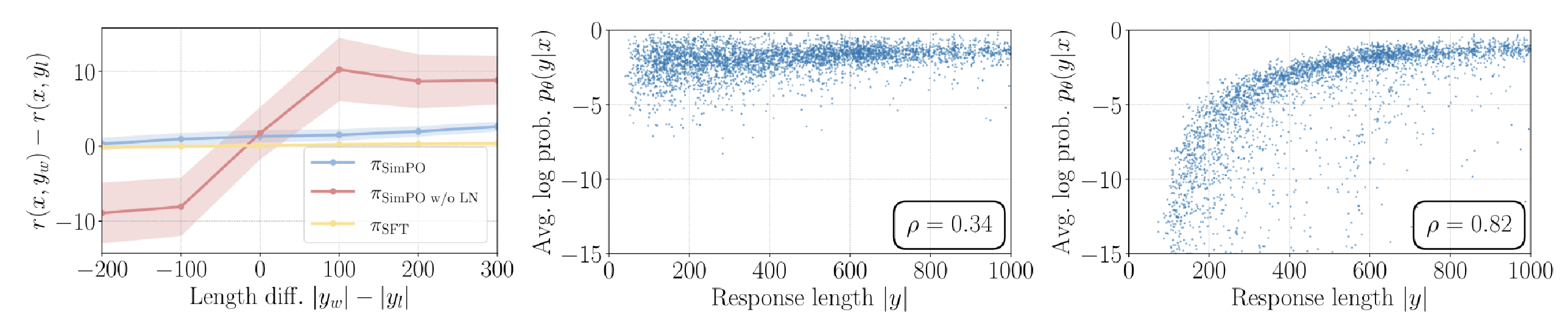 Effect of length normalization on SimPO’s reward model. https://arxiv.org/pdf/2405.14734
Effect of length normalization on SimPO’s reward model. https://arxiv.org/pdf/2405.14734
In the above left chart, we see that when the model is trained without length normalization (LN) in red, the reward clearly depends on the length of the statements (higher reward when higher length!). Whereas, when the model is trained with LN (in blue), the reward is almost always positive and does not depend on the statement length. Plus, compared to the reference model (which has not been aligned with preferences), the reward is higher when aligned with SimPO.
In the other two plots, we look at the Spearman correlation between the length of the generated output and its likelihood for a given prompt when the model is aligned with and without length normalization. The correlation is way higher without LN (0.82! Which means higher generation length leads to higher statement likelihood) compared to with LN (0.34). This shows that normalization is crucial for making the aligned model more robust and not just generating long answers. The authors also checked this correlation for a model aligned with DPO, and the correlation coefficient for SimPO is lower than for DPO (0.59). This means SimPO looks to handle output length more robustly.
In addition to the expected outputs, we observe that the simpler design of the reward model also leads to better robustness regarding generated output length. Now that we have confirmed these important outcomes, let's now explore the general results to see if these improvements also enhance the overall capabilities of the LLM.
SimPO vs DPO: Stronger results
We already saw that the authors' results are aligned with their expectations regarding better alignment, faster computation and stronger robustness. Nevertheless, we need to tackle the most important points: does the SimPO also drive better LLM capacities?
Results on benchmarks
We already introduced the models used by the authors to compare their implementation: Llama 3-8B and Mistral-8B, considering both the Base model and the Instruct model in each case. They mainly assess the models using three of the most popular open-ended instruction-following benchmarks: MT-Bench, AlpacaEval 2, and Arena-Hard v0.1. These benchmarks test the models' conversational skills and are widely used by the community.
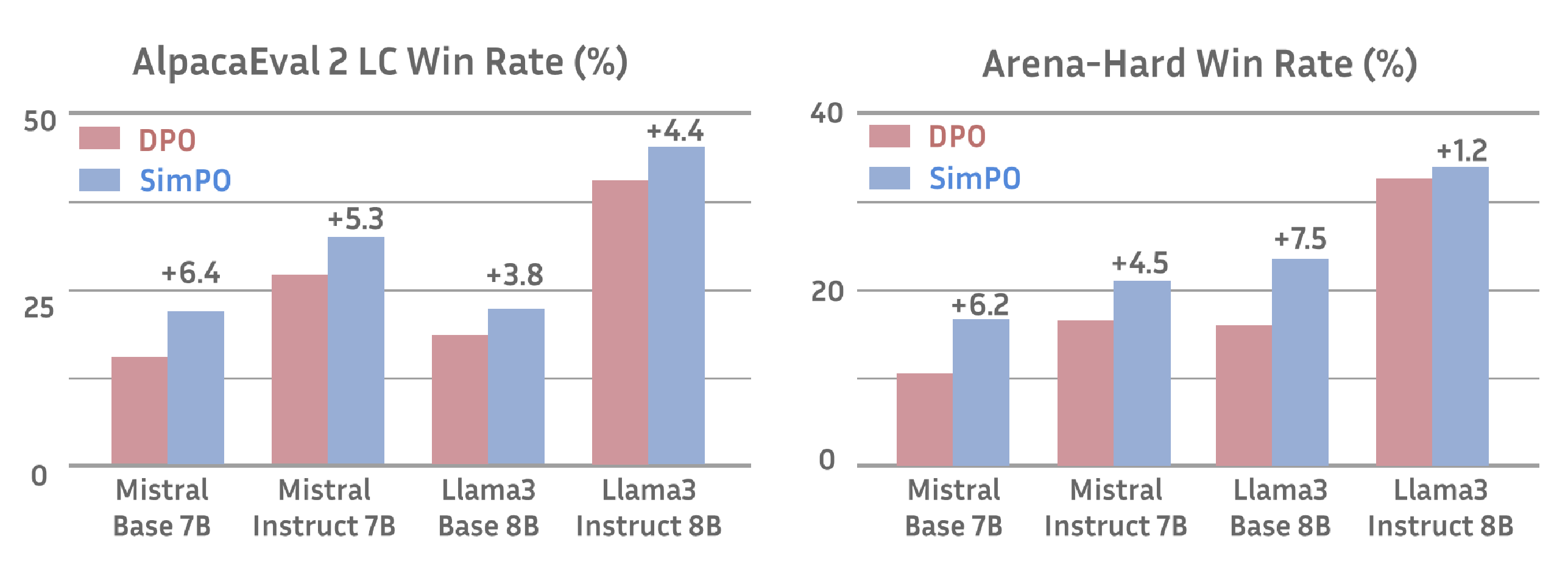 SimPO vs DPO on AlpacaEval2 and Arena-Hard Benchmarks. https://arxiv.org/pdf/2405.14734
SimPO vs DPO on AlpacaEval2 and Arena-Hard Benchmarks. https://arxiv.org/pdf/2405.14734
The results are straightforward when comparing SimPO with DPO. SimPO outruns existing preference DPO for each model type: Llama-3 or Mistral, Base or Instruct. Notably, SimPO outperforms the best baseline by 3.8 to 6.4 points on the AlpacaEval 2 LC win rate and by 1.2 to 7.5 points on Arena-Hard across various settings. These consistent and significant improvements highlight the robustness and effectiveness of SimPO compared to DPO.
The last result worth mentioning is the comparison between SimPO and other offline preference optimization processes (most of them were tackled in our previous blog posts).
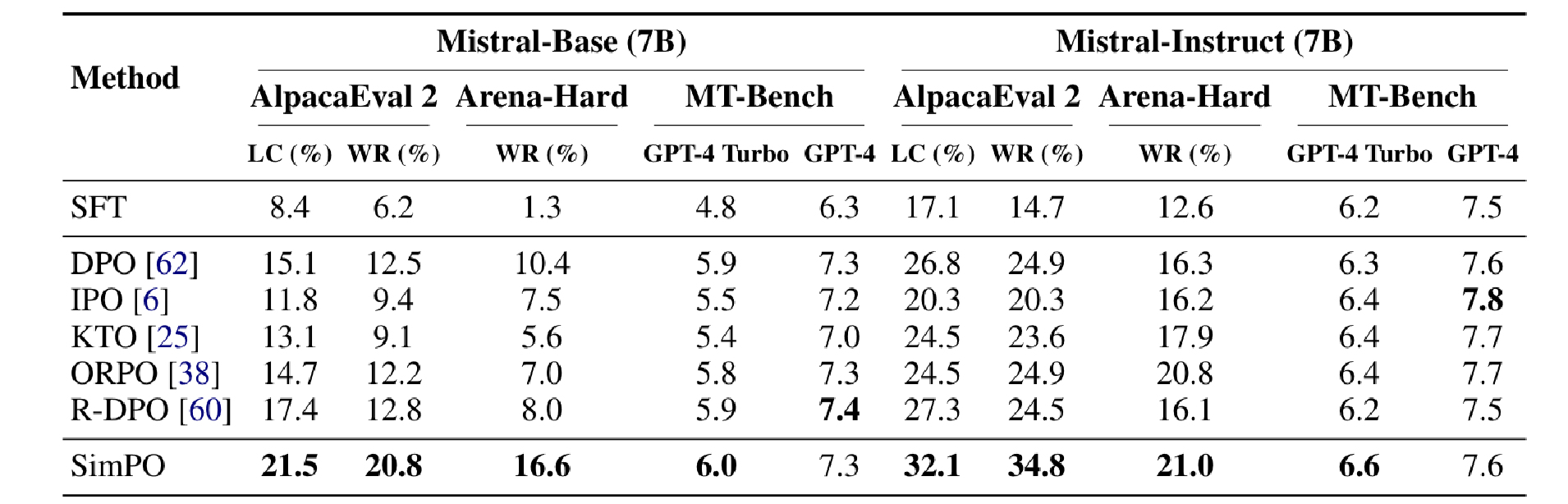
We see in bold that the SimPO reward model generally produces better results. But more importantly, even if the other strategies generally improve the results compared to the reference Supervised Fine-Tuned model, the DPO, here, empirically outperforms the other strategies except the R-DPO.
In conclusion, on the most important aspect of LLM abilities, the SimPO strategy also outperforms the DPO and its main variants on different benchmarks, highlighting the great results achieved by the authors.
One last thought on this paper comes from the limitations highlighted by the authors. The most important and interesting in our opinions: the theory behind the success of such a process is quite uncertain. While SimPO has shown impressive results and makes intuitive sense intuitively, the reward model field lacks theoretical analysis to fully understand why it works so well. And we can only thank the authors for such acknowledgement and transparency.
One concrete argument regarding the lack of understanding of such success is the hyperparameter set-up (the target reward margin), which needs to be adjusted manually, and further research should look into ways to gain a better theoretical understanding of how those models operate. Finally, this strategy has not been tested for the safety and honesty aspect, therefore before deploying such a system in real-world applications, one should need to test this kind of outcome.
Conclusion
In a nutshell, SimPO focuses on simplifying and making the design of reward models more intuitive to better align preferences with the metrics that guide the generation of the LLM. First, the implementation improves the LLM's abilities on various benchmarks. More importantly, these metric increases come with better alignment with our preferences, faster computation, and greater robustness regarding the length of the generated output. This is a promising work that should motivate researchers to better understand the theoretical framework of such processes.
Want to know more?
This is the eighth entry of a series of blog posts dedicated to alternatives to RLHF. The first, second, third, fourth, fifth, sixth, seventh, eight and tenth posts of the series can be found on our website too. Consult the overview to understand the advantages and disadvantages of the methods presented so far.
Argilla and Mantis NLP teams are happy to help with any question you may have about preparation steps for training a LLM using Supervised fine-tuning, Reinforcement Learning, or Direct Preference Optimization.
All the data curation steps are currently supported by Argilla’s Data Platform for LLM, and from Mantis NLP we offer end-to-end support for the whole process.


