
Introduction
This is a series of blog posts related to alternatives to Reinforcement Learning by Human Feedback, created as a joint effort between Argilla and MantisNLP teams. Please ensure you have gone through the previous entries in the series to fully understand the context and progression of the discussion before moving on to this segment. Scroll to the bottom of the page to go to the next blog post of the series.
In previous posts, we started by analyzing the efforts to carry out Supervised Fine-tuning (SFT) and Reinforcement Learning with Human Feedback (RLHF), and the importance of having high-quality data (first and second blog posts). Nevertheless, RLHF is complex and usually unstable, so we examined a promising alternative, Direct Preference Optimization (DPO), to align the LLM with human preferences without requiring RL (third blog post). Still, DPO does not solve all the shortcomings, for instance, a large amount of preference data is needed to fine-tune. To tackle this, researchers have come up with new methods. Some of them are Reinforcement Learning AI Feedback (RLAIF) or Self-Play Fine-Tuning (SPIN) (fourth and fifth blog posts). For better data alignment, we also explored the benefits of Identity Preference Optimization (IPO) and Kahneman-Tversky Optimization (KTO) (sixth and seventh blog posts). ORPO was also described as it simplified the alignment process (eight blog post). In the ninth blog post, we discussed in an overview the advantages and disadvantages of the methods presented so far.
In most cases, we work with what's called preference data, where we choose one answer between two given options. But what if we had to choose between two pairs of prompts and their responses? This is what DOVE proposes with Joint Preference Optimization.
From Conditional to Joint Preference Optimization
Language models typically rely on a ranking-based approach for alignment. In this method, responses to the same instructions are compared based on a fixed context. While this can be effective, it can also be limiting because it fails to fully capture the diverse and changing nature of human preferences. Such is the case with DPO, which has been the go-to strategy for aligning LLMs.
In reality, human preferences are based on broader criteria, that is, humans also express preference in contexts that are not identical. For instance, the original paper suggests that when buying an electronic product, you might prefer a review that is structured and detailed about its features and utilities. However, when looking for movie reviews, you might favor those that are more subjective and expressive.
Thus, the authors of Comparing Bad Apples to Good Oranges: Aligning Large Language Models via Joint Preference Optimization introduce a new framework that improves upon the traditional ranking-based approach. Instead of comparing responses based on identical instructions, this method compares pairs of instruction-response. This allows the model to capture both the linguistic aspects (such as adherence to instructions, grammatical fluency, and clarity) and the broader, context-dependent human preferences.
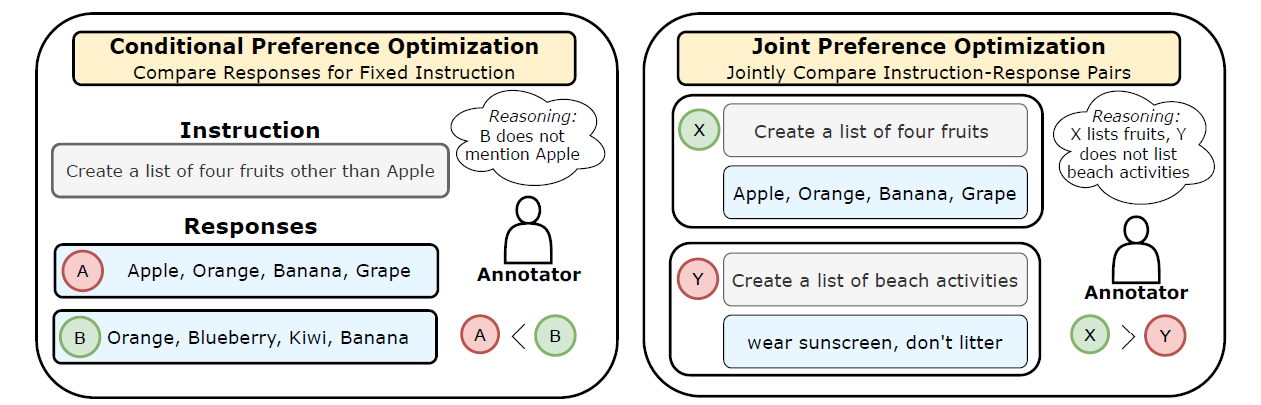 Difference between conditional preference optimization and joint preference optimization. Source: https://arxiv.org/abs/2404.00530
Difference between conditional preference optimization and joint preference optimization. Source: https://arxiv.org/abs/2404.00530
DOVE
To achieve joint preference optimization, DOVE is introduced as a new innovative framework. DOVE is a preference optimization objective designed to align language models by learning from preferences over instruction-response pairs.
Similar to the DPO approach, DOVE begins with a supervised fine-tuned language model. It then focuses on weighting the joint probability of preferred responses over non-preferred ones. This involves adjusting the conditional probability of preferred responses over non-preferred ones, along with a correction factor based on the prior probability of the instructions according to the language model.
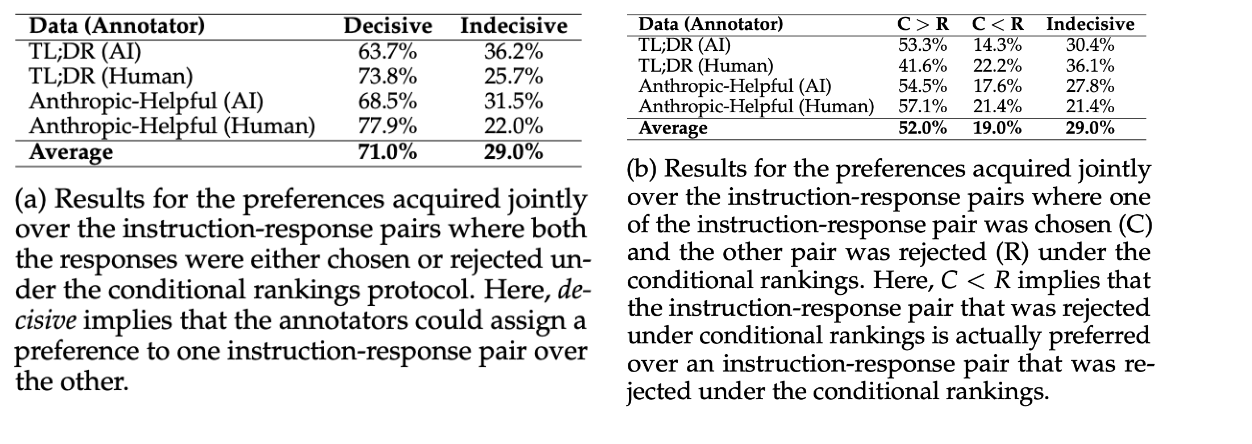
 Interplay between the conditional rankings and joint rankings and reasoning acquired from the human annotators. Even if in conditional ranking a response is preferred over the other in joint ranking this can vary. Source: https://arxiv.org/abs/2404.00530
Interplay between the conditional rankings and joint rankings and reasoning acquired from the human annotators. Even if in conditional ranking a response is preferred over the other in joint ranking this can vary. Source: https://arxiv.org/abs/2404.00530
To evaluate the interaction between conditional ranking and joint ranking, feedback from AI and human annotators was analyzed. The analysis revealed that in 71% of cases, annotators could make a decisive choice in a joint configuration, even when both responses were chosen or rejected in a conditional configuration. Additionally, annotators could sometimes favor a response that was previously rejected in the conditional configuration over a preferred one.
 Source: https://arxiv.org/abs/2404.00530
Source: https://arxiv.org/abs/2404.00530
DOVE vs DPO
For more details on the experiments and results, please refer to the original paper and the GitHub repository.
The results of aligning Mistral-7B demonstrate that DOVE can effectively utilize both conditional preferences (viewed as joint preferences with identical contexts) and joint preferences with non-identical contexts.
Additionally, it is claimed that an LLM trained using DOVE with instruction-response joint preference data outperforms one trained with DPO by 5.2% and 3.3% in winning percentage on the TL;DR and Anthropic-Helpful datasets, respectively.
The experiments also highlighted DOVE's robustness in aligning LLMs using only joint preferences on instruction-response data, without relying on conditional preferences. This approach not only simplifies the alignment process but also improves model performance across different contexts.
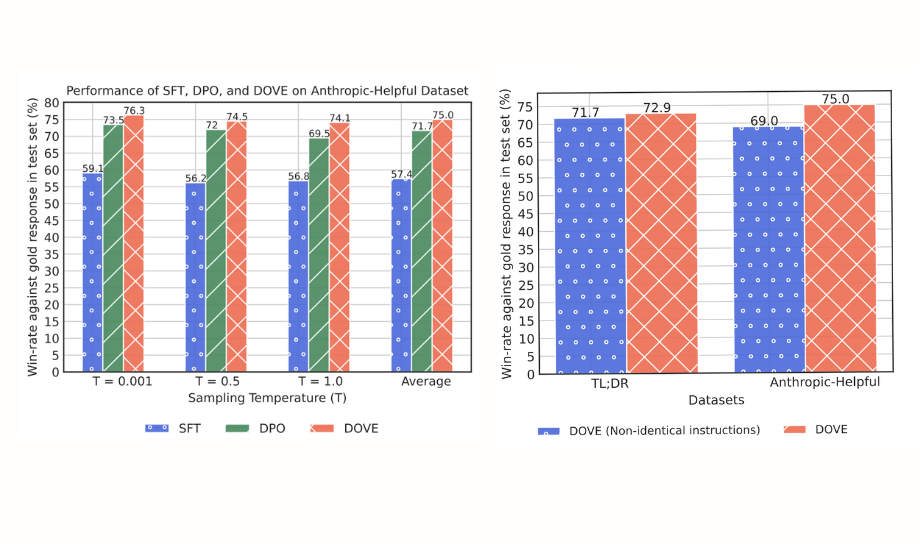 On the left, results for aligning LLMs with the DOVE preference optimization objective. On the right, the impact of the joint preferences over non-identical instructions using DOVE. Source: https://arxiv.org/abs/2404.00530
On the left, results for aligning LLMs with the DOVE preference optimization objective. On the right, the impact of the joint preferences over non-identical instructions using DOVE. Source: https://arxiv.org/abs/2404.00530
Conclusion
In summary, DOVE is an insightful approach to the alignment of large language models. It has proven to accurately capture a broader spectrum of human preferences by leveraging both conditional and joint feedback, making it a robust method. While further research is needed to understand its importance in different scenarios and against various benchmarks, this approach provides a new and helpful perspective on how human preferences work and the limitations we should face.
Want to know more?
This is the eighth entry of a series of blog posts dedicated to alternatives to RLHF. The first, second, third, fourth, fifth, sixth, seventh and eight posts of the series can be found on our website too. Consult the overview to understand the advantages and disadvantages of the methods presented so far.
Argilla and Mantis NLP teams are happy to help with any question you may have about preparation steps for training a LLM using Supervised fine-tuning, Reinforcement Learning, or Direct Preference Optimization.
All the data curation steps are currently supported by Argilla’s Data Platform for LLM, and from Mantis NLP we offer end-to-end support for the whole process.


