
This blog was originally published as part of a blog series on Medium as a collaborative effort with MantisNLP. See the previous part of this blog series here. Here, we analyzed the efforts required to carry out Supervised Fine-tuning on a pretrained LLM and how important the instruction data is for this step.
Reinforcement Learning by Human Feedback
Unfortunately, SFT alone is often insufficient for refining the large language models to meet specific requirements.
With it, you can complement the lack of information you may have in pretrained LLM, change the style, structure, teach to answer differently to different outputs.
However, there will always be multiple ways you can answer a question. State-of-the-art conversational models, such as ChatGPT, have been traditionally requiring an additional step called Reinforcement Learning by Human Feedback (RLHF).
Reinforcement learning is a paradigm in which an agent learns to make decisions by receiving feedback from its environment. In the context of language models, this feedback is provided by human reviewers who assess and rate the model's responses. By leveraging human expertise and judgments, reinforcement learning facilitates the iterative improvement of the model's performance and fine-tunes its responses.
The process of reinforcement learning by human feedback involves several important steps:
- Guidelines are defined to guarantee unique criteria when deciding what is a good and a bad answer to an input.
- A Reward Model (RM) should be trained, which will evaluate each of the responses in terms of accuracy, relevance, and adherence to guidelines.
- To train the RM, some prompts are selected and sent to human reviewers. We call them Preference Data (PD)
- The reviewers then interact with the model and manually evaluate and rate the corresponding outputs.
- The collected feedback, in the form of ratings or rankings, is used to train the RM.
- With the RM trained, we can train a Policy Optimizer, a required component which will guide the fine-tuning of the LLM.
- We fine-tune the LLM with Policy Optimization.
- This iterative feedback loop allows the model to gradually learn from human guidance and refine its behavior accordingly.
Preference Data
The main requirement at this point is having Preference Data (PD). Preference Data is a collection of options / alternatives to a prompt, which can be sent to a group of Annotators and/or Subject Matter Experts (SME) so that they rate it, given some annotation guidelines, from the best to the worst.
Several approaches have been used to create the Preference Data.
- For selecting the best prompts, you can either have a predefined set of them, have a predefined template and generate some on the fly, and or combine/those with random prompts from a database, for example.
- For selecting the answers, you can send the prompt to one specific version of the model (the last one you have fine-tuned) or to different checkpoints. Decide how many answers you want to rank: you can use just 2 and have a binary ranking schema of best-worst or have your annotators ranking from 1 to 5, as an example.
- Always define first the Annotation Guidelines for the different ranking levels, to minimize individual interpretations and standardize the answers.
There are also several datasets you can use, which you can find in this GitHub repository:
| Dataset link | Type | Size | Description |
| OpenAI WebGPT Comparisons | Question-Answering | 20k | 20k comparisons where each example comprises a question, a pair of model answers, and human-rated preference scores for each answer. RLHF dataset used to train the OpenAI WebGPT reward model. |
| OpenAI Summarization | Summarization | 64k | 64k text summarization examples including human-written responses and human-rated model responses. RLHF dataset used in the OpenAI Learning to Summarize from Human Feedback paper. |
| OpenAssistant Conversations Dataset (OASST1) | Conversations | 461k | A human-generated, human-annotated assistant-style conversation corpus consisting of 161k messages in 35 languages, annotated with 461k quality ratings, resulting in 10k+ fully annotated conversation trees |
| Stanford Human Preferences Dataset (SHP) | Question-Answering Instructions |
385k | 385K collective human preferences over responses to questions/instructions in 18 domains for training RLHF reward models and NLG evaluation models. |
| Reddit ELI5 | Question-answering | 270k | 270k examples of questions, answers and scores collected from 3 Q&A subreddits |
| Human ChatGPT Comparison Corpus (HC3) | Question-answering | 60k |
|
This is what the OpenAI Summarization Preference Data looks like (again, using Hugging Face Dataset viewer): given 1 prompt (left, a summarization task on an article), you have N answers (right, the summaries) with a ranking/score (in this case there are several axes/metrics, like accuracy, coverage, etc. being the final aggregated metric called ‘overall’)
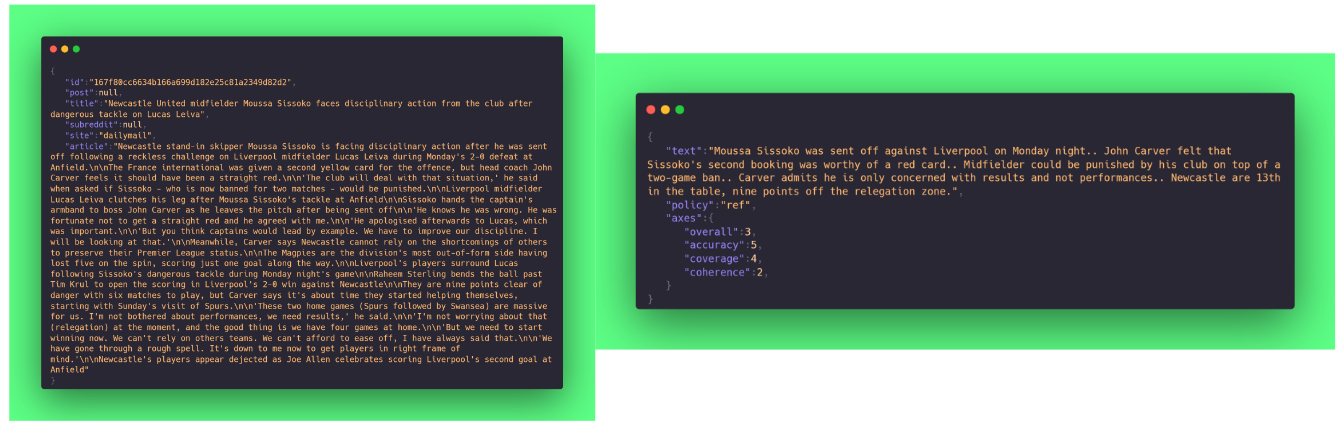
After collecting a dataset of prompts and answers (the Preference Data - PD), you can already send them to your Annotators for a review.
Let’s see how you can easily carry out a process of data collection and supervision for PD using Argilla’s Data Annotation Platform.
Preference Data with Argilla
Preference data implies ranking outputs from best to worst, as mentioned above. Argilla introduced RankingQuestion in version 1.12.0 to the FeedbackDatasets that can be used for this kind of ranking.
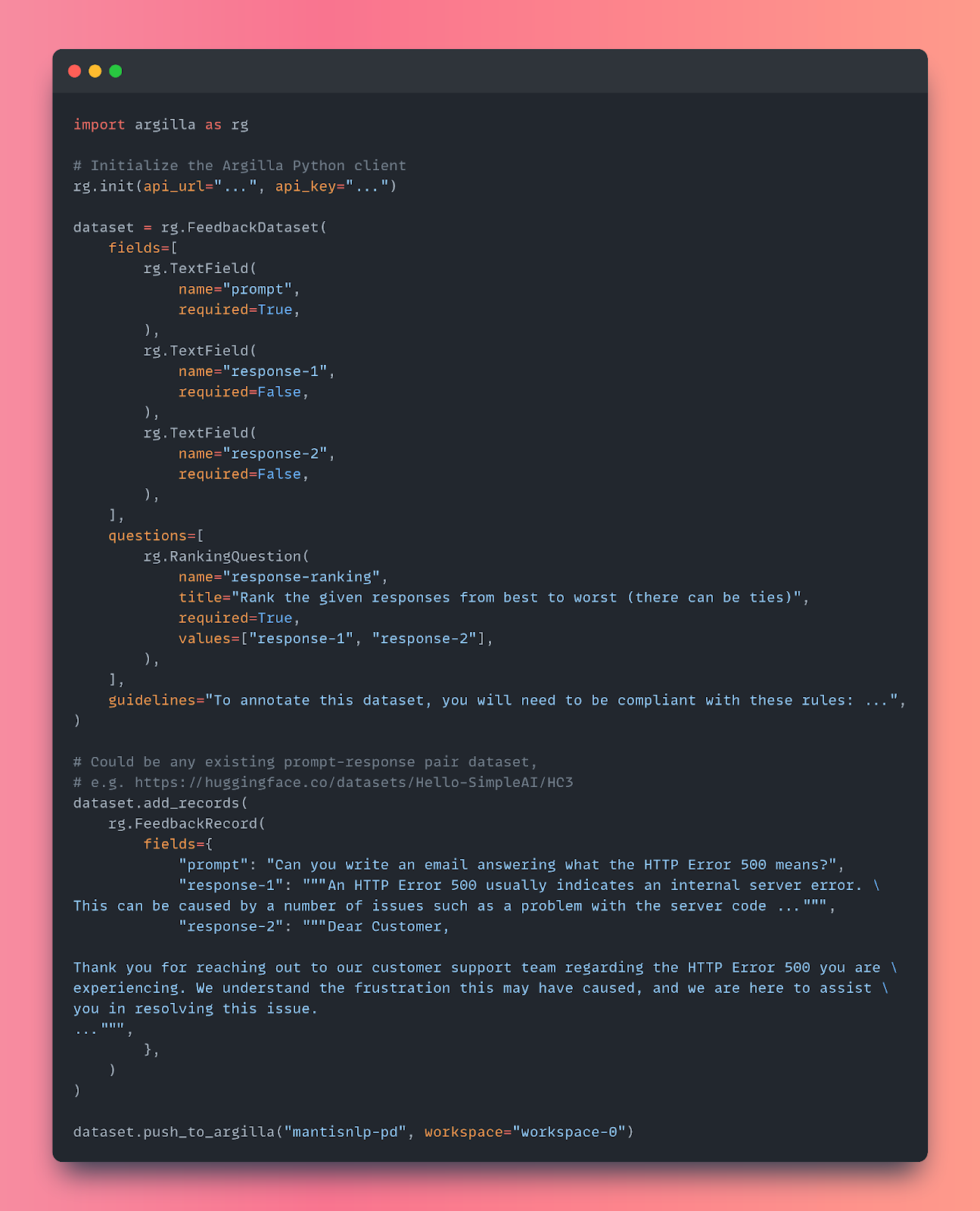
As a quick recap, FeedbackDatasets in Argilla require both a list of fields and a list of questions so that the annotators can provide answers to those. In this case, to rank the answers for a dataset as the one mentioned above, we would need the following:
TextFields to define both the prompts and the answers generated for those prompts.RankingQuestionto ask the annotators to rank the responses for a given prompt from best to worst, following the pre-defined annotation guidelines.
Translated to code, it would look like this:
Running the above in Argilla, would generate the following dataset in the Argilla UI, ready for the annotators to start ranking the answers to a collection of prompts, to later on be collected to train/fine-tune a Reinforcement Learning model based on Preference Data.
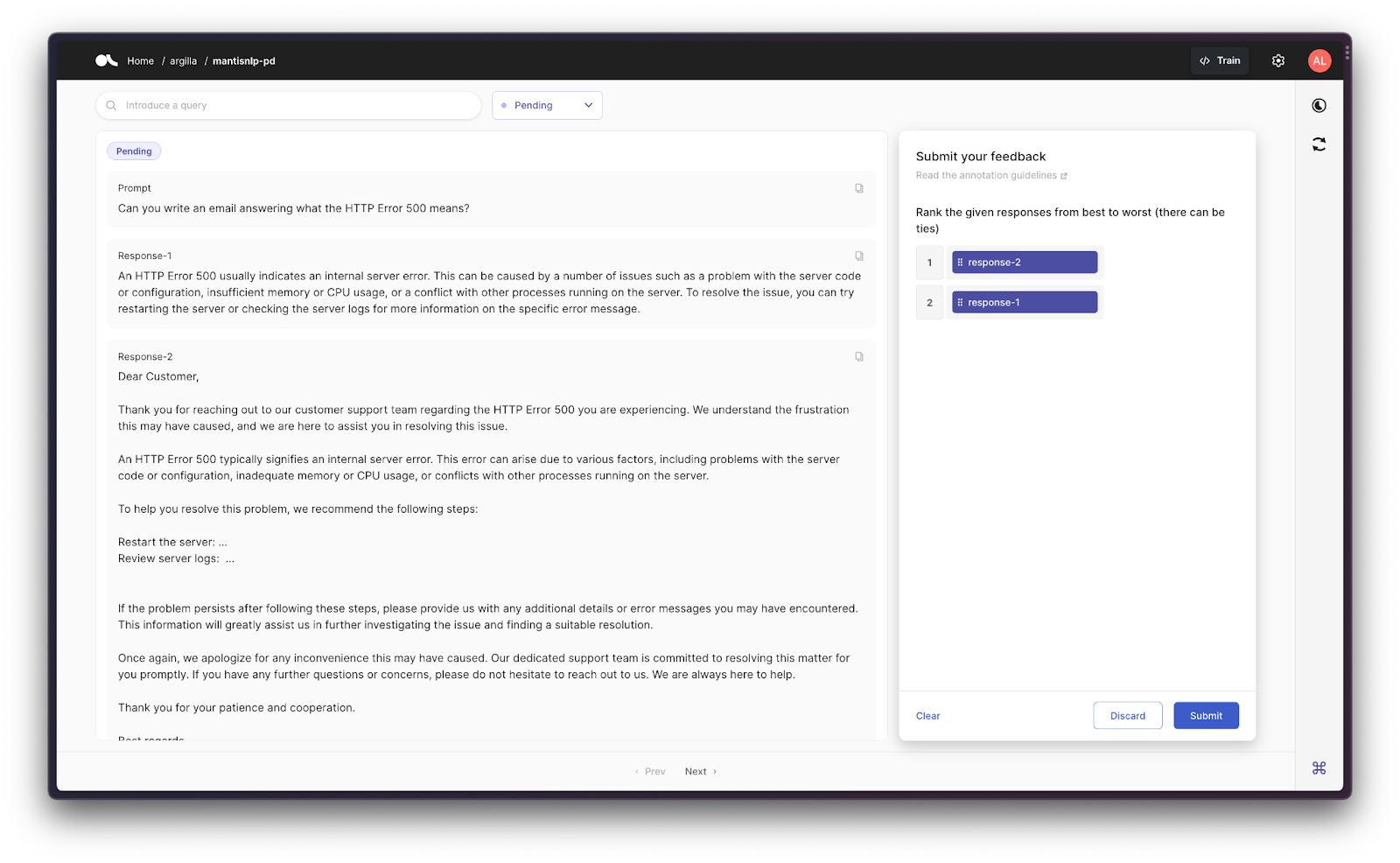
Number of ranking levels
Preference Data can contain several alternatives to be ranked from 0 to N. ChatGPT used 4 alternatives ranked from A to D (see figure below). However, simplified methodologies, as Direct Preference Optimization, will just require a binary classification of chosen vs rejected. With that, you could set up Argilla to just show, for example, two responses (Response-1 and Reponse-2) and choose the best as Chosen and the least preferred as Rejected.
Check the details about how you can prepare your data for RLHF with Argilla and then train a RLHF model using Hugging Face trl [3] library in this Argilla’s post [2] about LLM fine-tuning.
Instruction Data for fine-tuning vs Preference Data for Reinforcement Learning
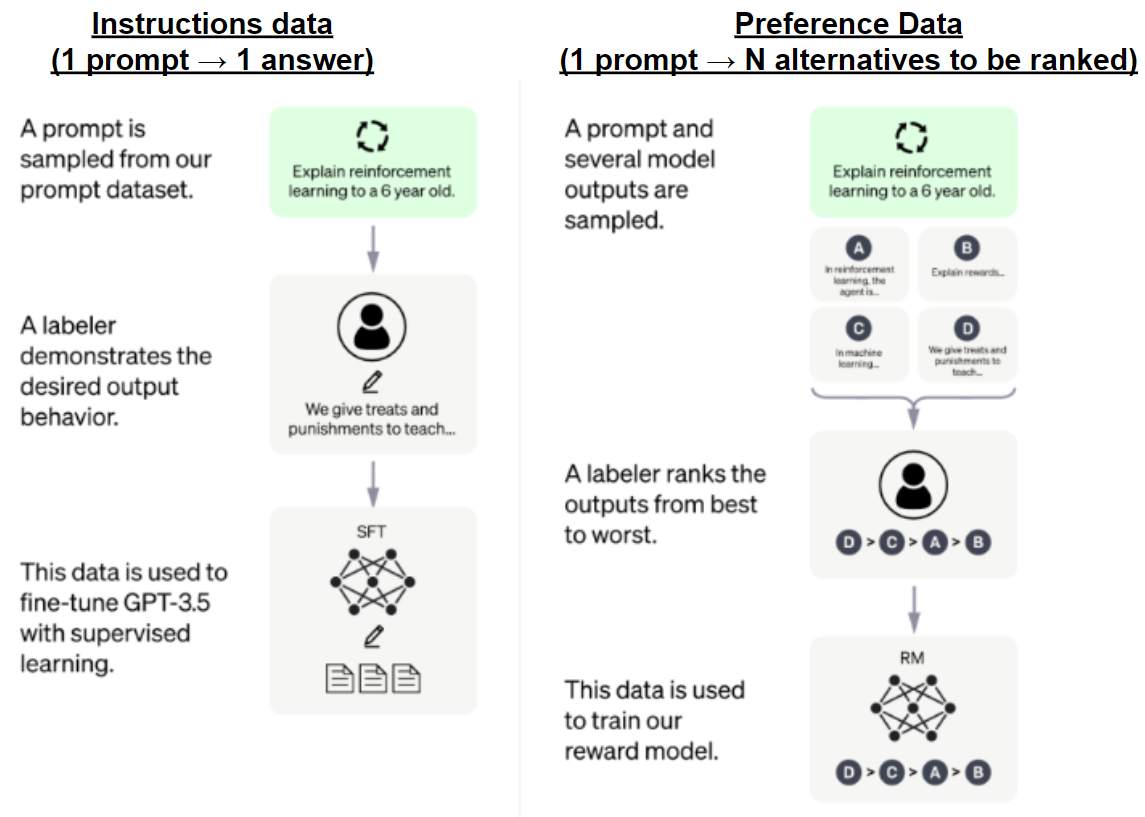
So far we have seen we need 2 datasets to get our LLM-based chatbot working: the Instruction Data for fine-tuning and the Preference Data for Reinforcement Learning. Let’s clarify the differences:
- The Instruction Data is used in the fine-tuning step, and consists of prompts and expected answers which aim to improve or correct the way an LLM generates text based on a prompt. You may even want to train the model on a generation of a new type of content, for example, a piece of advertisement, SEO content, a report, etc - and the model may not have been trained to do that! That is where Instruction Data comes into play, and consists of rows with 1 prompt and 1 generated example to it.
- The Preference Data is used to train a Policy (see next section). Basically, here you are not teaching the model anymore to write specific emails, or reports, or any content of your needs. You are training a Policy Model to make the model distinguish, given N acceptable answers to a prompt, which are better than others. Usually Preference Data is a collection of 1 prompt and N answers to that prompt, to then be ranked for a group of Annotators or Subject Matter Experts.
This is how ChatGPT depicts it:
Let’s talk now about how the Preference Data is used to train a Policy to optimize the quality of the answers taking into account the provided rankings.
The Reward Model and the Policy Optimizer
RLHF adds a big complexity to the process of training your custom LLM. In summary of what we described above. This is the picture which summarizes everything you need to do:
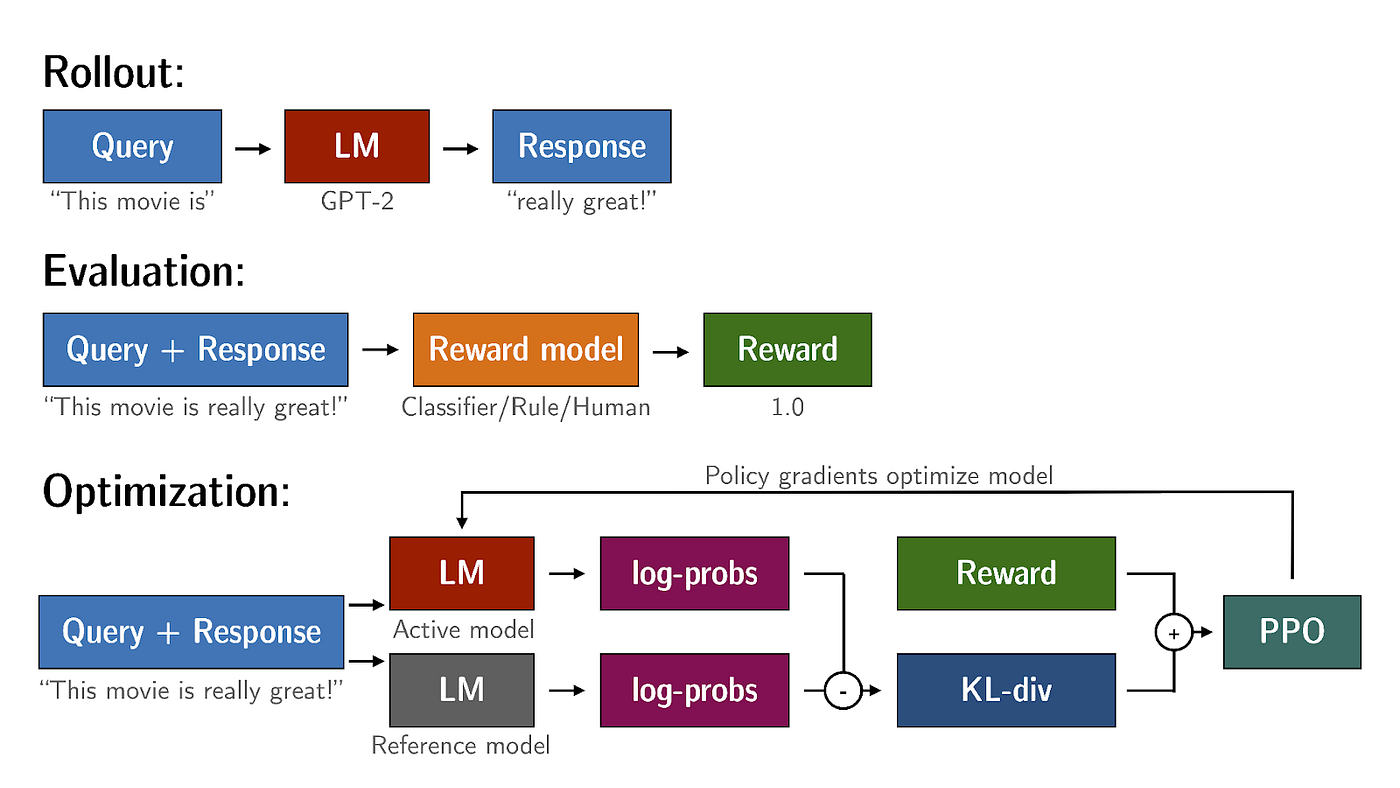
In summary, it requires the following artifacts:
- Annotation Guidelines to define what is a good or a bad answer.
- Preference Data: Selecting prompts for Human Labellers. Generating the outputs for evaluators.
- A Reward Model (RM);
- A Policy, optimized with the data from the RM;
It’s evident the process is complex and very expensive in terms of human and computational resources. But there are alternatives that combine the fine-tuning of the model (SFT) with the Reward Modeling, simplifying the process a lot. Let’s talk about them.
Want to know more?
This is the second entry of a series of blog posts dedicated to alternatives to RLHF. The first post of the series can be found here. See the next part of this blog series here.
Argilla and Mantis NLP teams are happy to help in any question you may have about preparation steps for training a LLM using Supervised fine-tuning, Reinforcement Learning or Direct Preference Optimization.
All the data curation steps are currently supported by Argilla’s Data Platform for LLM, and from Mantis NLP we offer end-to-end support of the whole process.


