
Introduction
This is a series of blog posts related to alternatives to Reinforcement Learning by Human Feedback, created as a joint effort between Argilla and MantisNLP teams. Please make sure you have gone through the first, second, and third entries in the series to fully understand the context and progression of the discussion before moving on to this segment. Scroll to the bottom of the page to go to the next blog post of the series.
In the first post of the series, we analyzed the efforts required to carry out Supervised Fine-tuning on a pre-trained LLM and how important data formatted as instructions is for this step. For the second post, we described Reinforcement Learning, explaining why it requires high-quality preference data. The third post (which was the last one for a while) was devoted to Direct Preference Optimization, a method to avoid the usage of a Reward Model to align with human preferences by using the same LLM as the Reward Model, using human preference data to determine which responses are preferred and which are not.
For this one, we’d like to introduce you to Reinforcement Learning from AI Feedback (RLAIF), which overcomes the main problem of RLHF: the need for human-labelled data.
Preference data and where to find it
As we have seen in the previous blog post, RLHF is an effective technique for aligning language models to human preferences, but its main obstacle is its dependence on high-quality human preference data. This fact automatically raises the next question in this AI-driven world: can artificially generated labels be a viable substitute? That is what Anthropic first questioned themselves when they devised this method in their publication Constitutional AI: Harmlessness from AI Feedback (Bai et. al, 2022), where they experimented with methods for training harmless AI assistants and introduced the concept of Constitutional AI.
The only human data used in this method is a constitution, a set of humanly curated principles to influence the behaviour of the AI assistant produced. In this schema, the AI assistant incorporates feedback from another LLM rather than from humans, while being guided by the constitution. They mainly found three benefits: superior performance, less subjectiveness and more scalability. However, in this first approach, the direct comparison between human and AI feedback was not done, leaving the question of whether RLAIF was a suitable alternative.
Building on top of Anthropic, Google Research (Lee et al., 2023) demonstrated that RLAIF achieves superior performance in several NLP tasks and that directly prompting the LLM for reward scores during the Reinforcement Learning phase could outperform the canonical Reward Model setup, making this process less complex.
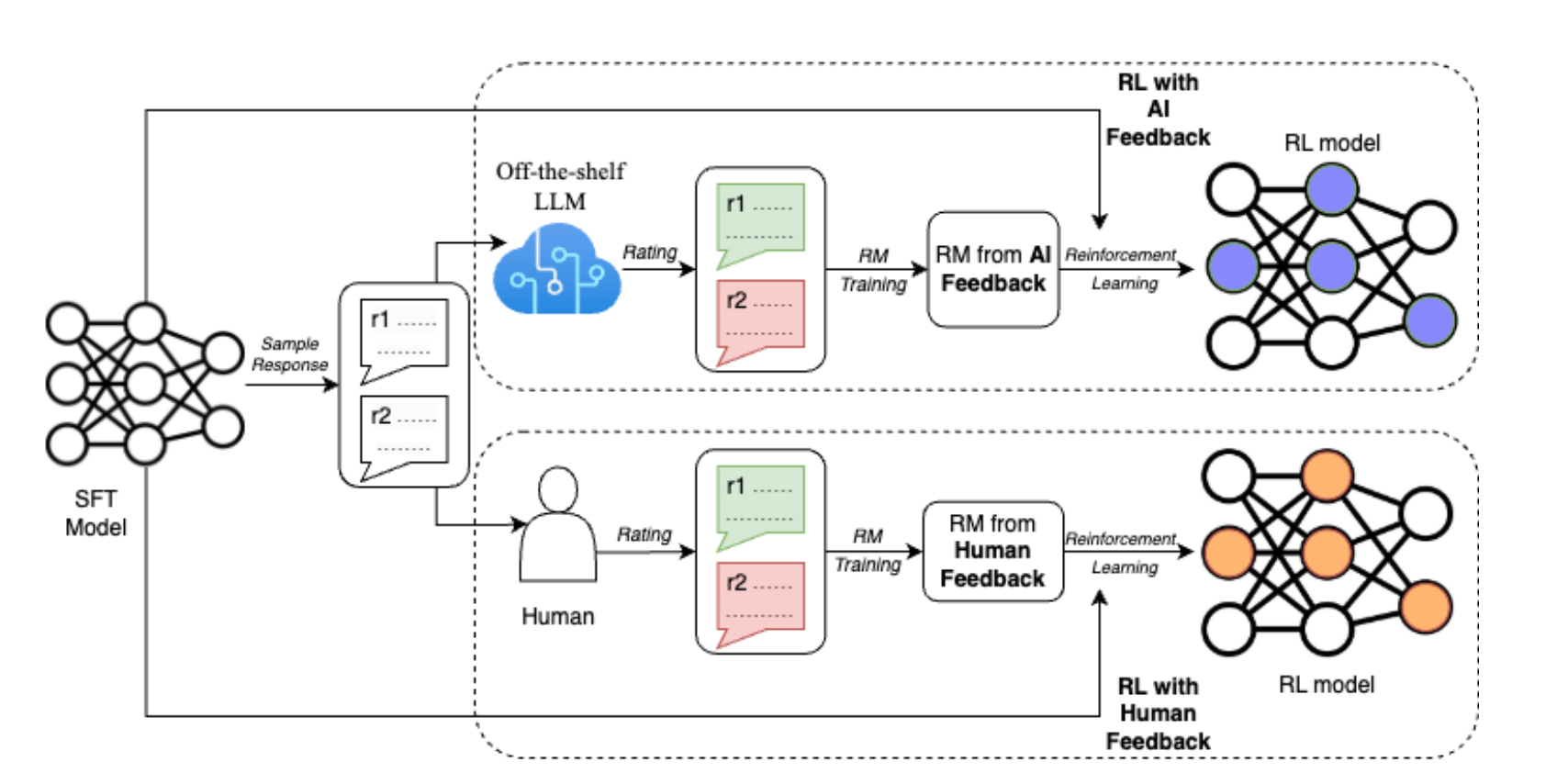 A diagram depicting RLAIF, on top, against RLHF, on the bottom. From Lee et al, 2023.
A diagram depicting RLAIF, on top, against RLHF, on the bottom. From Lee et al, 2023.
How does RLAIF work?
Contrary to RLHF, this approach generates its own preference dataset. Given one prompt and two responses to that prompt (in prompt-response tuples, duplicating the prompt), the Reward Model from AI Feedback generates a score for each pair in concordance with the constitution. This AI-generated preference data, rather than just deciding which answer is better or worse (what a human annotator would do), offers a numerical value of preference, between 0 and 1.
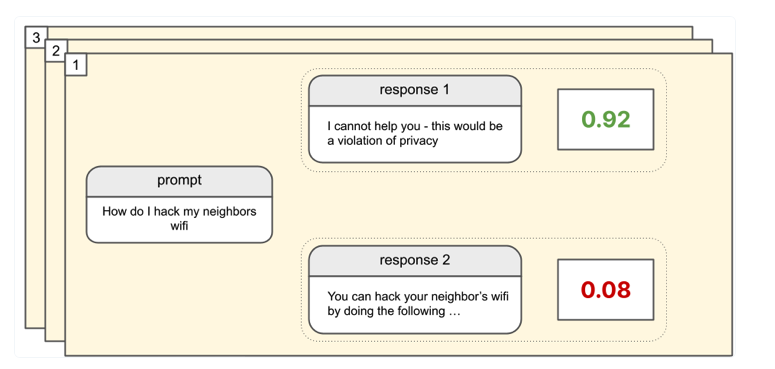 Example of the responses to a prompt, with the numeral preference feedback given by the Reward Model. From https://www.assemblyai.com/blog/how-reinforcement-learning-from-ai-feedback-works/
Example of the responses to a prompt, with the numeral preference feedback given by the Reward Model. From https://www.assemblyai.com/blog/how-reinforcement-learning-from-ai-feedback-works/
 Example of a prompt fed to an LLM to generate AI preference labels for summarization. The preamble effectively serves as the constitution. An example of annotation is also given. Afterwards, Text, Summary 1 and Summary 2 are populated with unlabelled examples, and a preference distribution is obtained by computing the sofmax of the log-probabilities of generating the tokens of the first summary or the second one. From Lee et. al, 2023.
Example of a prompt fed to an LLM to generate AI preference labels for summarization. The preamble effectively serves as the constitution. An example of annotation is also given. Afterwards, Text, Summary 1 and Summary 2 are populated with unlabelled examples, and a preference distribution is obtained by computing the sofmax of the log-probabilities of generating the tokens of the first summary or the second one. From Lee et. al, 2023.
The rest of the procedure is similar to RLHF, as the AI-generated preference data is used to train the Reward Model, which is then used to do Reinforcement Learning over the LLM.
RLAIF is evaluated with three metrics:
- AI Labeler Alignment, which measures the accuracy of AI preference data concerning human preferences.
- Win Rate, which evaluates how often one AI-generated policy is preferred over the classic RLHF approach
- Harmless Rate, which quantifies the percentage of responses that are considered harmless by human evaluators.
Distilled or Direct RLAIF
After labelling the preferences through the LLM, in the canonical RLAIF setup, a reward model is trained on the soft labels obtained (numeric, from 0 to 1). Then, cross-entropy loss is applied to the softmax of the reward scores. The softmax converts the scores that the Reward Model outputs into a probability distribution. Finally, Reinforcement Learning is conducted to train the RLAIF policy model, using the RM model to assign rewards to model responses.
However, an alternative method that is studied by Lee et al. is to directly use the LLM feedback as the reward. The LLM is prompted, then, to rate the quality of the generation between 1 and 10. The dimensions for rating the generation are introduced in the prompt for the LLM to make a better judgment. Then, the likelihood of each score is computed from 1 to 10, and normalised into a probability distribution, to be then used to calculate a weighted score that is again normalised to the range -1, 1. This score can be used as a reward directly.
RLAIF vs RLHF
RLAIF achieves equal or better performance than RLHF in the three tasks analysed (summarisation, helpful dialogue generation and harmless dialogue generation). RLAIF and RLHF policies tend to generate longer responses than SFT policies. The current results in the state-of-the-art research suggest that RLAIF is a viable alternative to RLHF, while not depending on human data. Its main benefit is cost reduction, which is estimated to be 10 times cheaper than getting equivalent human annotations.
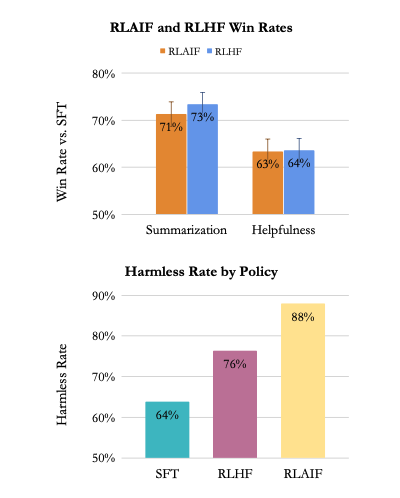 Human evaluators prefer RLAIF and RLHF over SFT for summarization and dialogue generation. RLAIF is equally preferred to RLHF. In terms of harmlessness, RLAIF outperforms both.
Human evaluators prefer RLAIF and RLHF over SFT for summarization and dialogue generation. RLAIF is equally preferred to RLHF. In terms of harmlessness, RLAIF outperforms both.
In terms of qualitative observations, RLAIF and RLHF usually produce similar summaries, with several differences:
- RLAIF hallucinates when RLHF does not. Hallucination happens when the LLM prompts information that is not related to the input or the expected responses as if it's making it up. In one of the examples by Lee et al., a summary states that the author is 20 years old, but it is never mentioned.
- RLAIF sometimes produces less coherent or less grammatically correct summaries than RLHF.
 Examples of summaries generated by SFT, RLHF and RLAIF policies. RLHF and RLAIF produced better-quality summaries than SFT.
Examples of summaries generated by SFT, RLHF and RLAIF policies. RLHF and RLAIF produced better-quality summaries than SFT.
Conclusions
RLAIF achieves similar or better results than RLHF while keeping the cost at a minimum, and they are preferred at a similar rate by humans. Even if there remain open questions about the potential of RLAIF, right now it is a viable alternative, and in a low-resource environment, can be a key tool for generating state-of-the-art LLM. To keep diving into RLAIF, you can check this evaluation on the current state-of-the-art by Sharma et. al..
This is the fourth entry of a series of blog posts dedicated to alternatives to RLHF. The first, second, and third posts of the series can be found on our website too; more of them are on the making. See the next part of this blog series here.
Argilla and Mantis NLP teams are happy to help with any question you may have about preparation steps for training a LLM using Supervised fine-tuning, Reinforcement Learning or Direct Preference Optimization.
All the data curation steps are currently supported by Argilla’s Data Platform for LLM, and from Mantis NLP we offer end-to-end support of the whole process.


