
Introduction
This is a series of blog posts related to alternatives to Reinforcement Learning by Human Feedback. Please ensure you have gone through the first, second, third, fourth, fifth, and sixth entries in the series to fully understand the context and progression of the discussion before moving on to this segment. Scroll to the bottom of the page to go to the next blog post of the series.
In previous posts, we started by analyzing the efforts to carry out Supervised Fine-tuning (SFT) and Reinforcement Learning with Human Feedback (RLHF), and the importance of having high-quality data (first and second blog posts). Nevertheless, RLHF is complex and usually unstable, so Direct Preference Optimization (DPO) was introduced, to align the LLM with human preferences without requiring the Reinforcement Learning step (third blogpost). Still, DPO does not solve all the shortcomings, for instance, a large amount of preference data is needed to fine-tune. To tackle this, researchers have come up with new methods. Some of them are Reinforcement Learning AI Feedback (RLAIF) or Self-Play Fine-Tuning (SPIN) (fourth and fifth blog posts). In the sixth series of the blogpost, we discuss how Identity Preference Optimization (IPO) aims to enhance data alignment and mitigate overfitting.
For this post of the series, we will dive into KTO, a new way of aligning LLMs by using Prospect Theory.
Prospect Theory
Aligning LLMs with human feedback has been key to advance the state of the art of generative models. As seen in prior blog posts, preference alignment after SFT is proven to be more effective than SFT alone. In this paper by Stanford University and Contextual AI, they frame these current results through the lens of the Prospect Theory, by Daniel Kahneman and Amos Tversky.
A key finding of prospect theory is loss aversion, the phenomenon whereby the emotional impact of a loss is greater than the corresponding impact of an equivalent gain. Loss aversion creates a preference for options associated with a lower chance of incurring a loss. It makes us risk averse. (Annie Duke)
Published in 1979, and crucial for the decision to award Kahneman the 2002 Nobel Memorial Prize in Economics, this theory describes how individuals assess their gain and loss perspectives in an asymmetric manner. We, humans, are more sensitive to losses than gains, and, when faced with an uncertain event, we will likely make decisions that do not maximize the expected value. For example, given a gamble that might return
 Original representation of a hypothetical value function by Kahneman and Tversky. The value function that passes through the reference point is asymmetrical, steeper for losses than gains, indicating this concept of loss aversion. From the Prospect Theory paper.
Original representation of a hypothetical value function by Kahneman and Tversky. The value function that passes through the reference point is asymmetrical, steeper for losses than gains, indicating this concept of loss aversion. From the Prospect Theory paper.
Prospect Theory turned out to be the most significant work Kahneman and Tversky did and it is one of the most often cited among social sciences. If you want to dig further into the topic, you can check this video by Pete Judo or this overview
HALOs and KTO
Popular alignment methods, like PPO and DPO, model those human biases described by the Prospect Theory, and therefore, they can be defined as human-aware loss functions or HALOs. Although there is no distinction making HALOs better than non-HALOs per se, the current state of the art shows that those loss functions under the HALO definition work better than those that are not.
The Kahneman-Tversky Optimization (KTO) process directly maximizes the utility of generations instead of maximizing the log-likelihood of the preferences. KTO only requires a binary signal of whether output is desirable or not, which is a kind of data easier to obtain than preferences.
But, does being a HALO matter? Does this concept of modeling human biases in loss functions result in practical benefits for alignment? After experimentally comparing them on a variety of Pythia and Llama models with different parameter sizes and under identical settings and data, it was proven that HALOs either matched or outperformed the non-HALOs at all scaled, even though the gap is only significant in models with 13 billion parameters or more. For models up to 7 billion parameters, alignment alone provides virtually no gains over SFT alone.
Kahneman-Tversky Optimization
KTO builds on top of the KL-constrained RLHF objective functions, plugging in expressions from the Kahneman-Tversky model of human utility, while also adding some changes to make it compatible with LLMs. It works by adding a KL penalty that rises if the model increases the reward of a desirable example in a generic way. This forces the model to learn what makes an output desirable so that the reward can be increased while the KL is kept flat.
While comparing PPO with DPO, they discovered that +1/-1 reward signals were performing as well as DPO, if not better. This means that, instead of using data where two prompts are compared and ranked depending on which one the user prefers, the annotations consisted of a positive signal if the instruction or prompt was useful or acceptable, or negative if they were not. This unexpected success indicates that a signal like this may be sufficient to reach DPO-level performance.
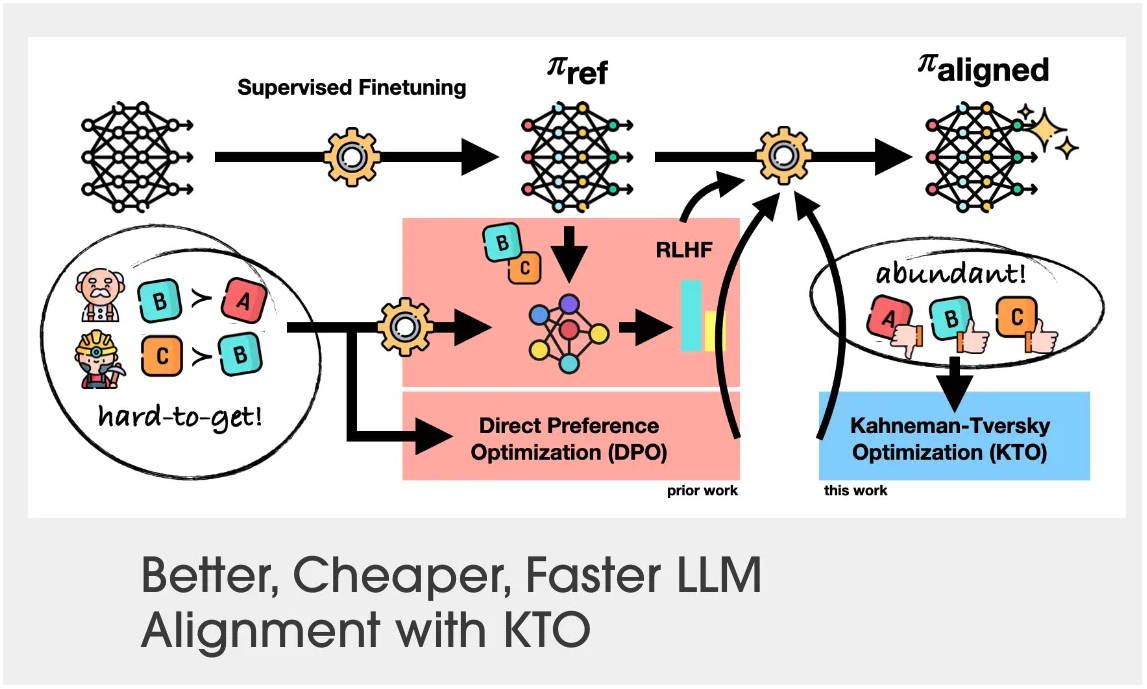 Overview of the process, by ContextualAI.
Overview of the process, by ContextualAI.
Thanks to this insight, they developed a HALO using the Kahneman-Tversky model of human utility, which allows them to optimize directly for utility with only a binary signal of whether output is desirable or not for a given input. The process is called Kahneman-Tversky Optimization (KTO) and gives access to state-of-the-art alignment feeding on data that is more abundant, cheaper and easier to collect than preference data.
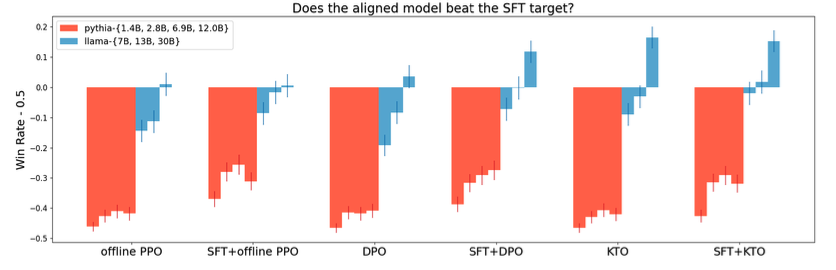 KTO is good or better than DPO at all scales, preceded or not by an SFT process. For the Llama models, KTO alone matches the performance of SFT and DPO combined, and is better than DPO alone. Error bars denote a 90% binomial confidence interval.
KTO is good or better than DPO at all scales, preceded or not by an SFT process. For the Llama models, KTO alone matches the performance of SFT and DPO combined, and is better than DPO alone. Error bars denote a 90% binomial confidence interval.
After some experimentation, two very interesting results arose:
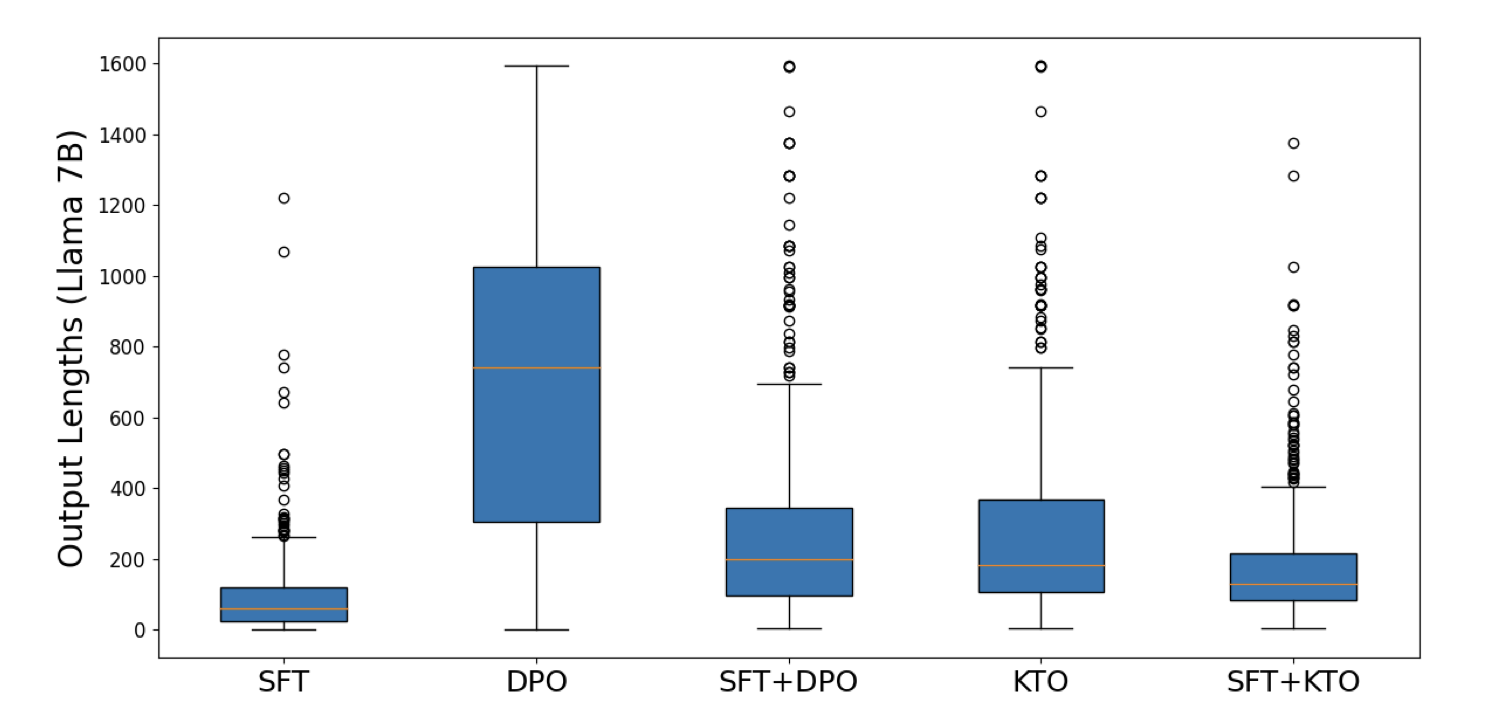
- Without doing SFT first, DPO-aligned models tend to ramble and hallucinate entire conversations. KTO does not suffer from this phenomenon.
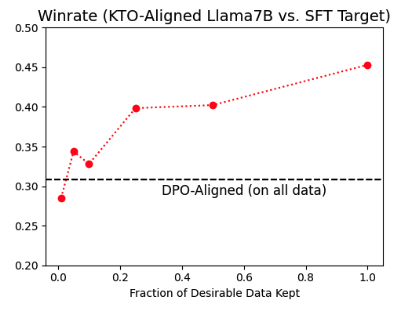
- After discarding 90% of the desirable examples while keeping the undesirable data, a KTO-aligned Llama-7B model still outperforms DPO. This implies that preference pairs do not necessarily have to be the source of KTO data.
When to KTO and when to DPO?
If the human feedback available is in binary format, or if there is an imbalance between desirable and undesirable examples, KTO excels. If the data is in the form of preference, the choice becomes less clear. The theoretical analysis suggests that if data has relatively low noise and intransitivity, DPO will work better, as there is some risk of KTO underfitting. However, if there is noise, the better worst-case guarantees KTO outperforming DPO.
Most of the publicly available datasets are proven to be noisy, with human preferences contradicting each other. This explains why KTO matched or exceeded the DPO performance in the experiments made. AI feedback can be noisy and intransitive too, so DPO may also be the best choice in that scenario.
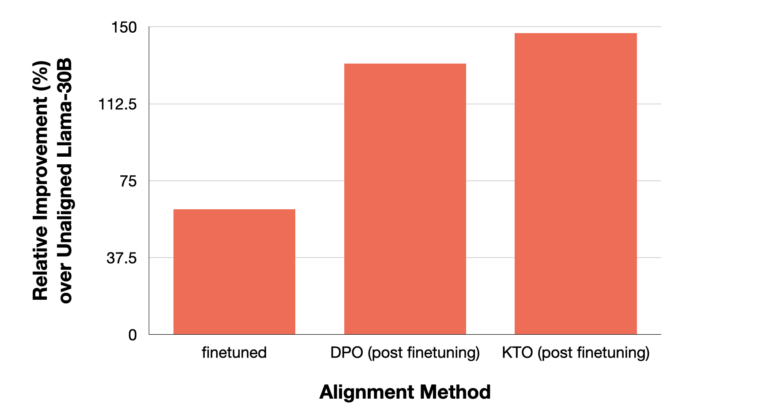 Comparison by ContextualAI over the existing methods done by aligning models up to 30B. Kahneman-Tversky Optimization provides a big increase in performance over the unaligned model, both over standard finetuning and DPO..
Comparison by ContextualAI over the existing methods done by aligning models up to 30B. Kahneman-Tversky Optimization provides a big increase in performance over the unaligned model, both over standard finetuning and DPO..
Conclusions
This work introduces HALOs, a class of human-aware loss functions, based on the work of Kahneman and Tversky in modeling how humans face uncertainty and win/loss scenarios. It shows that among existing alignment methods, those that can be considered HALOs perform better than those that do not. It also introduces a human-aware loss called KTO for directly maximizing the utility of generations by only learning from binary signals. KTO is as good or better as DPO from 1B to 30B.
There is still much work to be done, as the existence of HALOs raises many questions. What value function and HALO best describe how humans perceive language? How far can we push synthetic data? What other kinds of models can we synthetically optimize with KTO?
Want to know more?
This is the seventh entry of a series of blog posts dedicated to alternatives to RLHF. The first, second, third, fourth, fifth, and sixth posts of the series can be found on our website too.
Argilla and Mantis NLP teams are happy to help with any question you may have about preparation steps for training a LLM using Supervised fine-tuning, Reinforcement Learning, or Direct Preference Optimization.
All the data curation steps are currently supported by Argilla’s Data Platform for LLM, and from Mantis NLP we offer end-to-end support for the whole process.


