
Today, we are excited to announce the first release candidate of Argilla 2.0. This new version has a huge positive impact in the entire product and aims to broaden the support of diverse AI projects through extensible feedback tasks.
Argilla now moves from a task-centric approach to an extensible feedback model, allowing core NLP, AI, and LLM-related tasks to be handled through a unified framework. Whether you're working on Text Classification, Named Entity Recognition (NER), Machine Translation, Text Summarization, Question Answering, Large Language Models (LLMs), Speech Recognition, or Conversational AI, Argilla can simplify human feedback collection with flexible configurations for all project types.
The unique value of Argilla lies in its ability to streamline diverse feedback tasks, making it easier than ever to create high-quality datasets. By unifying tasks into a single, extensible feedback framework, users can focus on building better, more effective, and more accountable AI solutions.
The Journey from Argilla 1.0 to Argilla 2.0
Argilla is an open-source collaboration platform for AI engineers and domain experts to build high quality datasets. We make open-source, human-centric software to build more robust, sustainable, and accountable AI solutions. We believe the key to better AI solutions is better and higher quality data.
Since its inception in 2021 as a small community of NLP enthusiasts, Argilla has grown into a larger community of AI practitioners. Many AI teams are now integrating Argilla into their development workflows. As a community-driven project, Argilla 2.0 is grounded on valuable insights from continuous community feedback.
Adapting human feedback to the rise of LLMs
With the surge in LLM usage in late 2022, Argilla provided an open-source alternative for text annotation, efficiently handling core NLP tasks like Text Classification, Named Entity Recognition, and Text-to-Text processing. Argilla's unique value at the time was based on:
- Seamless integration with external tools, enhancing flexibility and functionality for various MLOps workflows.
- A powerful approach to data exploration and bulk annotation, enabling efficient and insightful data processing.
Recognizing the impact of LLMs, we introduced the Feedback Dataset, which allowed domain experts to provide feedback on LLM inputs and outputs by configuring a set of questions, similar to a form.
Over the past 12 months, Argilla has transitioned from task-centric datasets focused on natural language processing tasks to extensible feedback datasets targeting complex or multiple tasks. This year-long transition included covering the majority of previous functionalities, rebuilding the SDK, rewriting the docs, and adding novel key features.
From task-specific data labeling to feedback questions
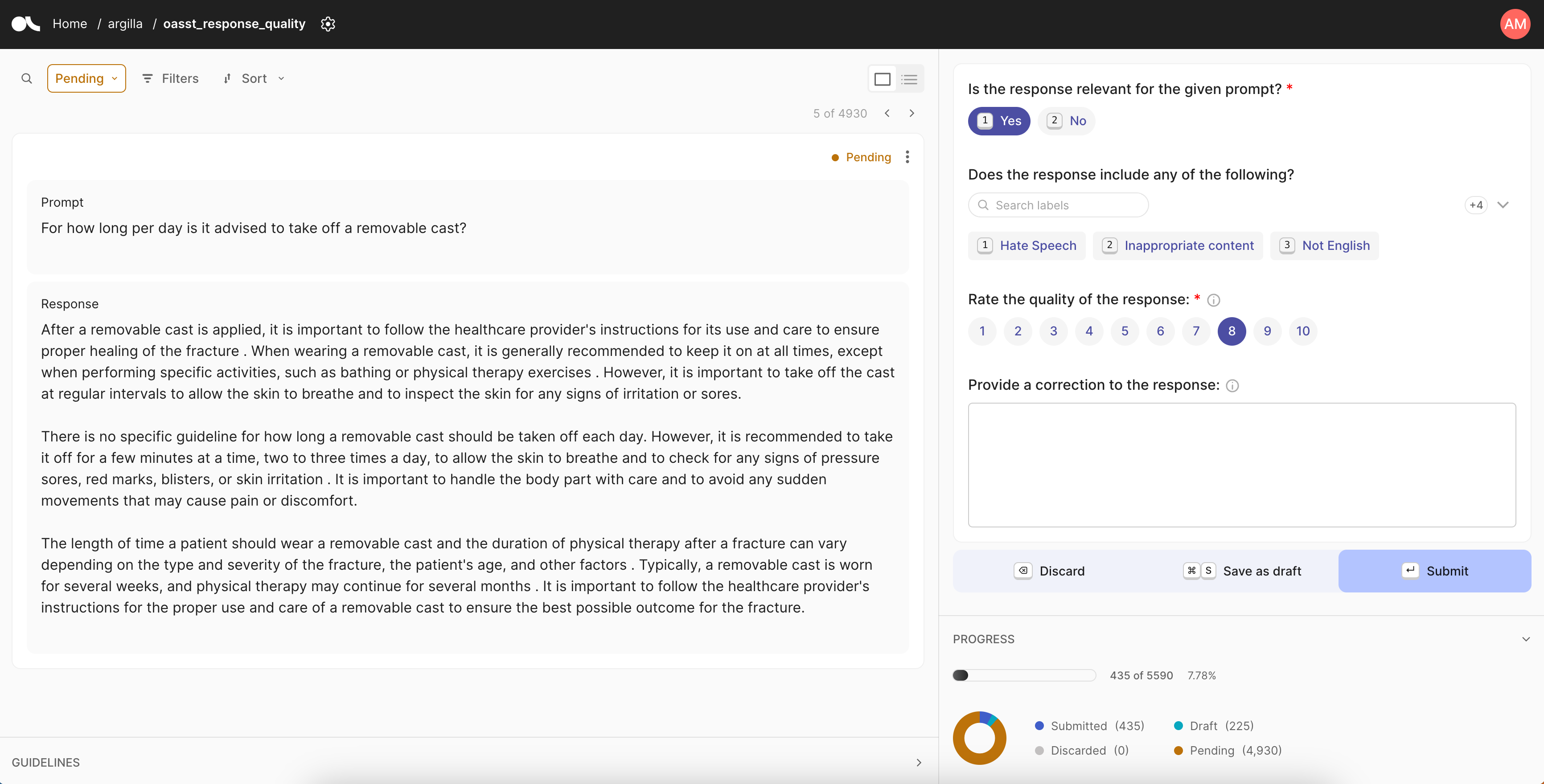
As AI models evolve rapidly, teams of all sizes tackle a vast array of use cases, all aiming to build and evaluate models based on high-quality custom datasets. Argilla 2.0 introduces a new workflow that empowers users to choose from a variety of question templates, including Rating, Ranking, Text, Multi-label, Single-label, and Span questions. This flexibility enables teams to collect human feedback for virtually unlimited use cases (e.g., NLP, LLMs) and purposes (e.g., training, evaluation), allows for precise fine-tuning of the data used to train LLMs. Additionally, by combining different feedback tasks, annotators can provide more comprehensive feedback and, at the same time, spend their valuable time more effectively.
Empower your annotators as domain experts
At Argilla we see annotators as competent domain experts that deeply understand the use case they're working on, and when given the right tools, can supply informed feedback that improves data quality. Therefore, Argilla 2.0 continues to build UI features for searching, filtering, and reviewing records. We focused on two main areas: flexible layouts and improved filtering.
Flexible layouts mean that labellers can define the most effective view of records based on the feedback task. They can adapt the split of fields vs questions to focus on wider content in one area. Or they can bring metrics and guidelines into constant view to understand the task.
Searching on fields allows annotators to control how they search for records with multiple fields by specifying the field to search in.
Refining the SDK for ease of use
Recently, we asked the community for their opinion on the SDK’s development. We talked to users from different backgrounds, from those deploying Argilla in production to those learning Argilla and human-centric ML for the first time. We also spoke with users tackling classical NLP tasks like classification and with those working on advanced LLM projects like Direct Preference Optimization datasets. From those discussions, we’ve learned two main things about the SDK:
- They loved and needed the switch to extensible tasks through the
FeedbackDataset. - The growing functionality was becoming difficult to learn and stay up to date with.
Argilla’s 2.0 SDK is the result of a multi-month effort aiming to unify and simplify Argilla’s developer experience while keeping the flexibility of Feedback Datasets. If you’d like to learn more about the design process and see a code walkthrough, don’t miss this video from Ben.
Upcoming features beyond Argilla 2.0
Once Argilla 2.0 we’ll start releasing a bunch of new exciting features. Here’s an overview of some of the things we have planned.
Task distribution
Argilla will enable a minimal setup to distribute the feedback task across available users . By configuring a minimum of submitted responses for a record to be considered complete, project admins will ensure the quality of collected feedback and make the most out of the effort of domain experts. This feature is the first step towards more advanced collaboration and team management features.
Multimodal support
Multimodal AI is becoming a reality. To improve multimodal models with human feedback, Argilla users can make use of HTML within the record fields. We're working on improving the user experience with a built-in ImageField. This new type of field will enable a more powerful and flexible way for collecting human feedback for computer vision and vision language models.
Using this built-in field, users can set up feedback workflows with our current questions (rate an image, describe an image, rank two images, and so on). Once we release this feature, we'll gather interest from the community for other computer vision tasks like image segmentation, object detection, etc.
No-code dataset creation
Currently, Argilla projects are started by ML/AI engineers deploying the application and defining feedback tasks. However, domain experts should also be able to start projects and improve datasets. For example, UI users should be able to select a dataset repo on the hub, define a feedback task, and improve that dataset in Argilla UI. We believe that creating datasets from the UI can empower users to get started without needing to know python. This will revolve around deep integration with the Hugging Face Hub and a new dataset creation flow in the Argilla UI.
How to get started
We highly recommend you browsing the new docs and get started with this guide.
If you want to contribute and shape the future of Argilla, you can upvote features and participate in Argilla’s public roadmap.


