
This blog was originally published on Medium as a collaborative effort with MantisNLP. See the next part of this blog series here.
Introduction
In recent years, the field of natural language processing (NLP) has witnessed remarkable advancements, primarily fueled by the development of large language models like GPT-3.5. These models, capable of generating coherent and contextually relevant text, have revolutionized various applications, ranging from chatbots and virtual assistants to content generation and translation. However, despite their impressive capabilities, these models often lack precision, exhibit biases, and struggle with nuanced understanding. This is where the importance of supervised fine-tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF) comes into play.
However, RLHF ”...is a complex and often unstable procedure, first fitting a reward model that reflects the human preferences, and then fine-tuning the large unsupervised LM using reinforcement learning to maximize this estimated reward without drifting too far from the original model.” [1].
In this article, Mantis NLP and Argilla team have joined efforts to showcase the alternatives to RLHF, more specifically Direct Preference Optimization (DPO) and Chain of Hindsight, including a hands-on on Argilla’s annotation platform to prepare the human preference data (PD) and the Transformers Reinforcement Learning (trl) library to fine-tune the Large Language Model (LLM) using DPO.
Supervised fine-tuning (SFT)
Large language models are typically pre-trained on massive amounts of text data, enabling them to learn the statistical regularities of language. However, they do not possess specific knowledge about particular domains or exhibit a comprehensive understanding of context. To bridge this gap, fine-tuning is employed, which involves training the model on domain-specific or task-specific datasets. Fine-tuning allows the model to acquire specialized knowledge and adapt its behavior to better serve specific applications, making it more useful and reliable.
Supervised fine-tuning (SFT) is a more focused approach that involves training a model on a labeled dataset that directly maps inputs to desired outputs. SFT, including instruction-tuning, teaches a model to respond based on what humans define.
To clarify the difference, let’s have an example. Imagine we are creating a conversational agent to solve customer support doubts about your software. Let’s suppose you use a foundational Large Language Model, for example, Falcon-7B, while the model you will generate will be a fine-tuned version of it.
Falcon can produce texts with high quality, but it may not match the style or specificity you are looking for, since it has been pre-trained to predict the next token in a sequence and not to predict tokens based on a specific task - a bot that emulates how your customer support team would answer.
This is an example input:
Can you write an email answering what the HTTP Error 500 means?
To this, Falcon (40B version) answers:
An HTTP Error 500 usually indicates an internal server error. This can be caused by a number of issues such as a problem with the server code or configuration, insufficient memory or CPU usage, or a conflict with other processes running on the server. To resolve the issue, you can try restarting the server or checking the server logs for more information on the specific error message.
The response is correct in terms of content, but it does not match the requirements of customer support messages, which usually:
- Sound more polite;
- Have a clear format;
- Are focused on providing instructions to solve the problem;
- Contain information about what to do if the problem continues.
So on, the corrected response for that prompt should be something similar to:
Dear Customer,
Thank you for reaching out to our customer support team regarding the HTTP Error 500 you are experiencing. We understand the frustration this may have caused, and we are here to assist you in resolving this issue.
An HTTP Error 500 typically signifies an internal server error. This error can arise due to various factors, including problems with the server code or configuration, inadequate memory or CPU usage, or conflicts with other processes running on the server.
To help you resolve this problem, we recommend the following steps:
- Restart the server: …
- Review server logs: …
If the problem persists after following these steps, please provide us with any additional details or error messages you may have encountered. This information will greatly assist us in further investigating the issue and finding a suitable resolution.
Once again, we apologize for any inconvenience this may have caused. Our dedicated support team is committed to resolving this matter for you promptly. If you have any further questions or concerns, please do not hesitate to reach out to us. We are always here to help.
Thank you for your patience and cooperation.
Best regards, Customer Support Representative
In order to have your LLMs produce texts which match your style and content guidelines, you need to fine-tune them using Supervised fine-tuning.
Supervised fine-tuning (SFT) based on Instructions
To carry out SFT on an LLM, you need data. More specifically, if you want to fine-tune a chatbot to successfully answer user requests, you need instruction data. There are many open source datasets (most of them with a non-commercial license!) which are instruction-based and you can use. This GitHub repository lists some of them:
| Dataset link | Dataset | Type | Language | Size | Description |
| GPT-4all Dataset | GPT-4all | Pairs | English | 400k entries | A combination of some subsets of OIG, P3 and Stackoverflow. Covers topics like general QA, customized creative questions. |
| RedPajama-Data-1T | RedPajama | PT | Primarily English | 1.2T tokens
5TB |
A fully open pretraining dataset follows the LLaMA's method. |
| OASST1 | OpenAssistant | Pairs,Dialog | Multilingual
(English, Spanish, etc.) |
66,497 conversation trees | A large, human-written, human-annotated high quality conversation dataset. It aims at making LLM generate more natural responses. |
| databricks-dolly-15k | Dolly2.0 | Pairs | English | 15K+ entries | A dataset of human-written prompts and responses, featuring tasks such as open-domain question-answering, brainstorming, summarization, and more. |
| AlpacaDataCleaned | Some Alpaca/ LLaMA-like models | Pairs | English | / | Cleaned version of Alpaca, GPT_LLM and GPTeacher. |
| GPT-4-LLM Dataset | Some Alpaca-like models | Pairs,
RLHF |
English,
Chinese |
52K entries for English and Chinese respectively
9K entries unnatural-instruction |
NOT the dataset used by GPT-4!! It is generated by GPT-4 and some other LLM for better Pairs and RLHF. It includes instruction data as well as comparison data in RLHF style. |
| GPTeacher | / | Pairs | English | 20k entries | A dataset contains targets generated by GPT-4 and includes many of the same seed tasks as the Alpaca dataset, with the addition of some new tasks such as roleplay. |
| Alpaca data | Alpaca, ChatGLM-fine-tune-LoRA, Koala | Dialog,
Pairs |
English | 52K entries
21.4MB |
A dataset generated by text-davinci-003 to improve language models' ability to follow human instruction. |
This is what the GPT4all fine-tuning dataset looks like in the Hugging Face Datasets Viewer. It’s pretty simple: it consists of a series of prompts (first column) and expected answers / responses (second column) to fine-tune the model answers to.
Although they may be used as a starting point, those datasets may not fit to your specific use case. If you want to have answers with your own formatting, as the one included in the previous section, you will need to create your own dataset. The data collection and reviewing mechanism can be very complex if you don’t have the proper tools.
Argilla’s Annotation Platform seems like a great option, since it already has options to curate data for the fine-tuning process and the preference data for the Reinforcement Learning by Human Feedback and the rest of the alternatives you will find in this post.
In addition, you can check Mantis NLP tutorial on Supervised fine-tuning for a more detailed explanation on Supervised fine-tuning using the trl library.
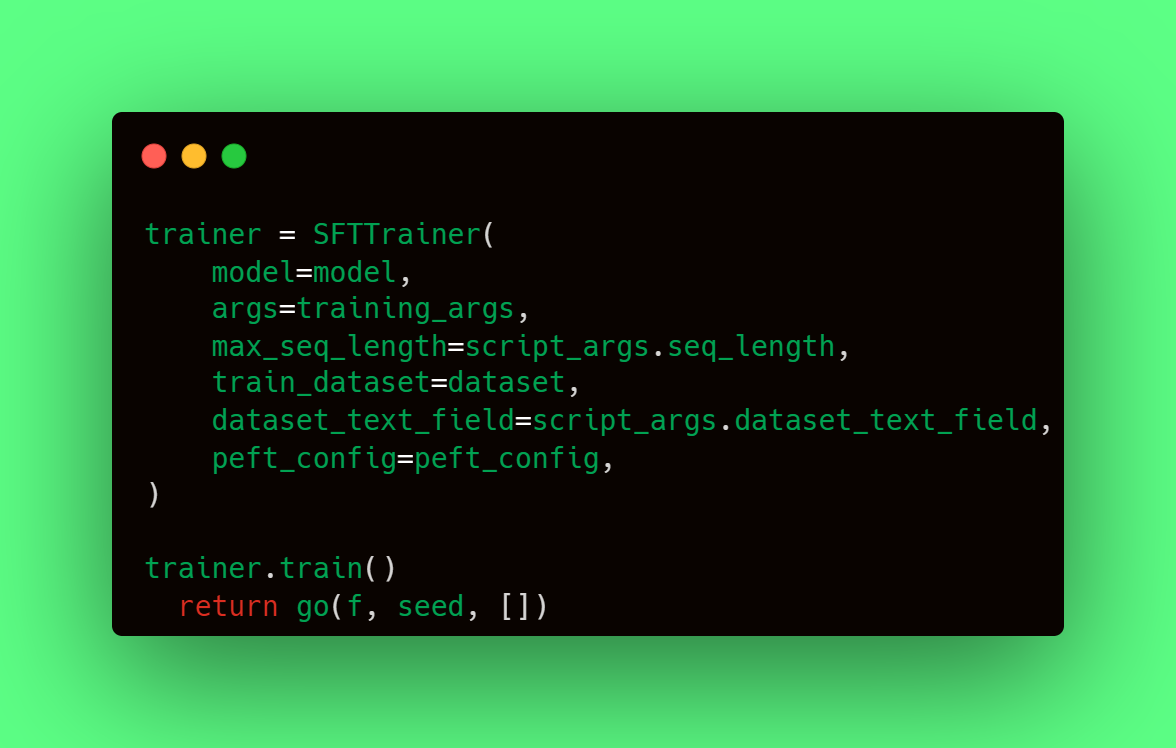
Supervised fine-tuning (SFT) based on Instructions with Argilla
Since most of those datasets have a non-commercial license, and while we can use them for fine-tuning with no commercial usage, we can use Argilla to create and curate our own instruction following dataset.
We can even synthetically generate a dataset to start with using existing LLMs, as Stanford did with Alpaca (reference at https://huggingface.co/datasets/tatsu-lab/alpaca), where they used OpenAI’s text-davinci-003 to collect the responses for a collection of prompts. However, always check the Terms of Services first before doing that - if it’s not for research, OpenAI TOS (as an example) explicitly prohibits using the "...output from the Services to develop models that compete with OpenAI;" (2.c.iii).
Whether we are synthetically generating a dataset or creating one from scratch, Argilla can be used to either edit the existing completions to a given instruction, if any, or just asking the annotators to provide a response/completion to it.
As of Argilla 1.8.0, the FeedbackDataset was introduced to allow users to create datasets to specifically collect feedback for LLMs, introducing more flexibility to the dataset fields definition and to allow multiple different annotations over the same records.
In this case, we will focus on instruction following datasets, but you can find more information about the latest Argilla updates and the FeedbackDataset specifically at https://argilla.io/blog/argilla-for-llms.
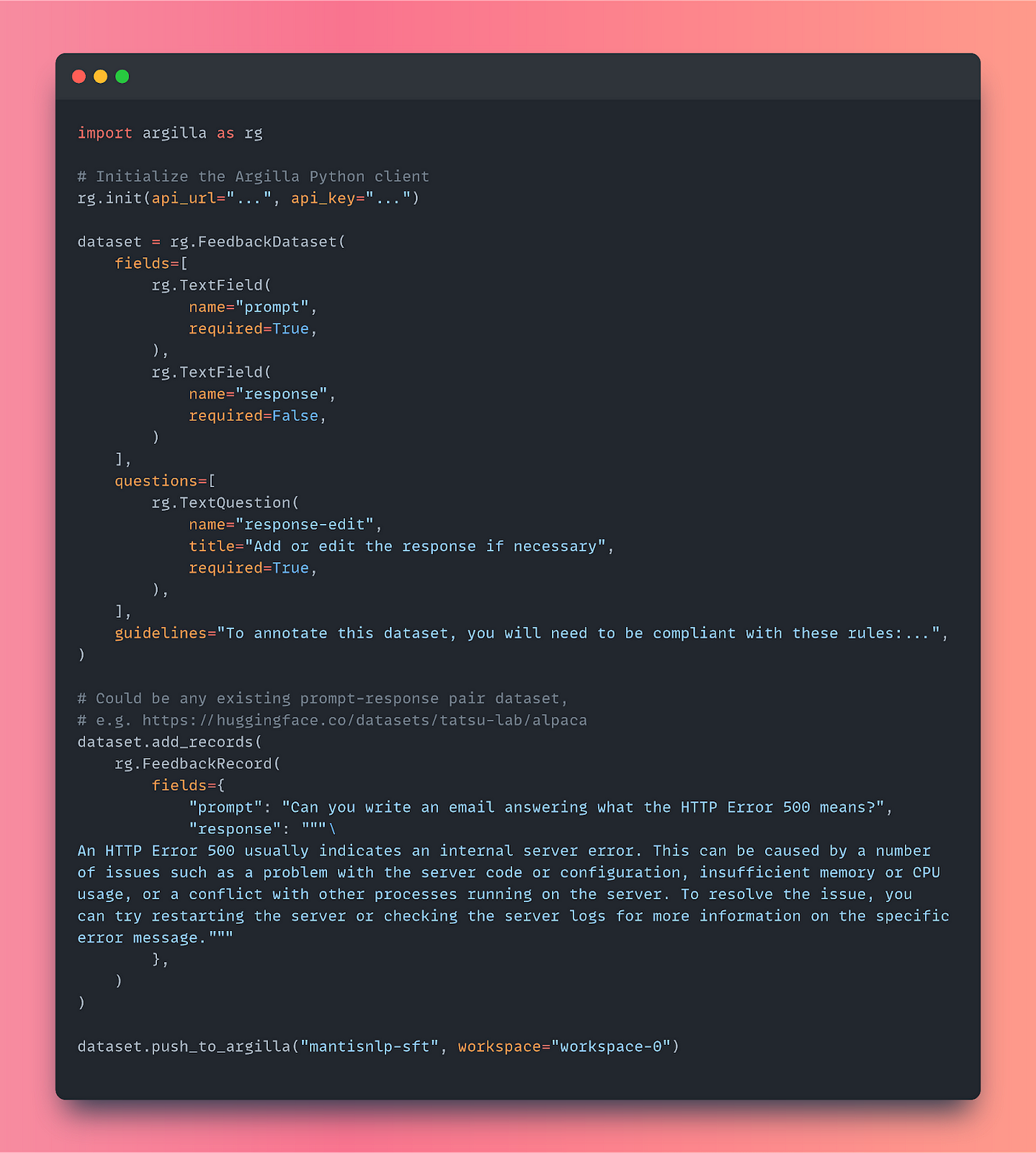
To create a FeedbackDataset for instruction following we should define the fields that would be present in our dataset, and also the question we want the annotators to answer to collect their feedback prior to the fine-tuning. So on, in this case we’ll need:
TextFields for the input.TextQuestionto ask the annotator to provide either a complete response or a response edit if any. These would come fulfilled with an existing suggestion if any, to help the annotator with the annotation process.
Finally, we should write down the annotation guidelines which will be required for the annotator to know what they should provide as a response in terms of style, politeness, etc. as mentioned above.
Translated to code, it would look like this:
Running the above in Argilla, would generate the following dataset in the Argilla UI, ready for the annotators to start providing or editing the existing responses if any, to later on be collected to fine-tune our own instruction following LLM.
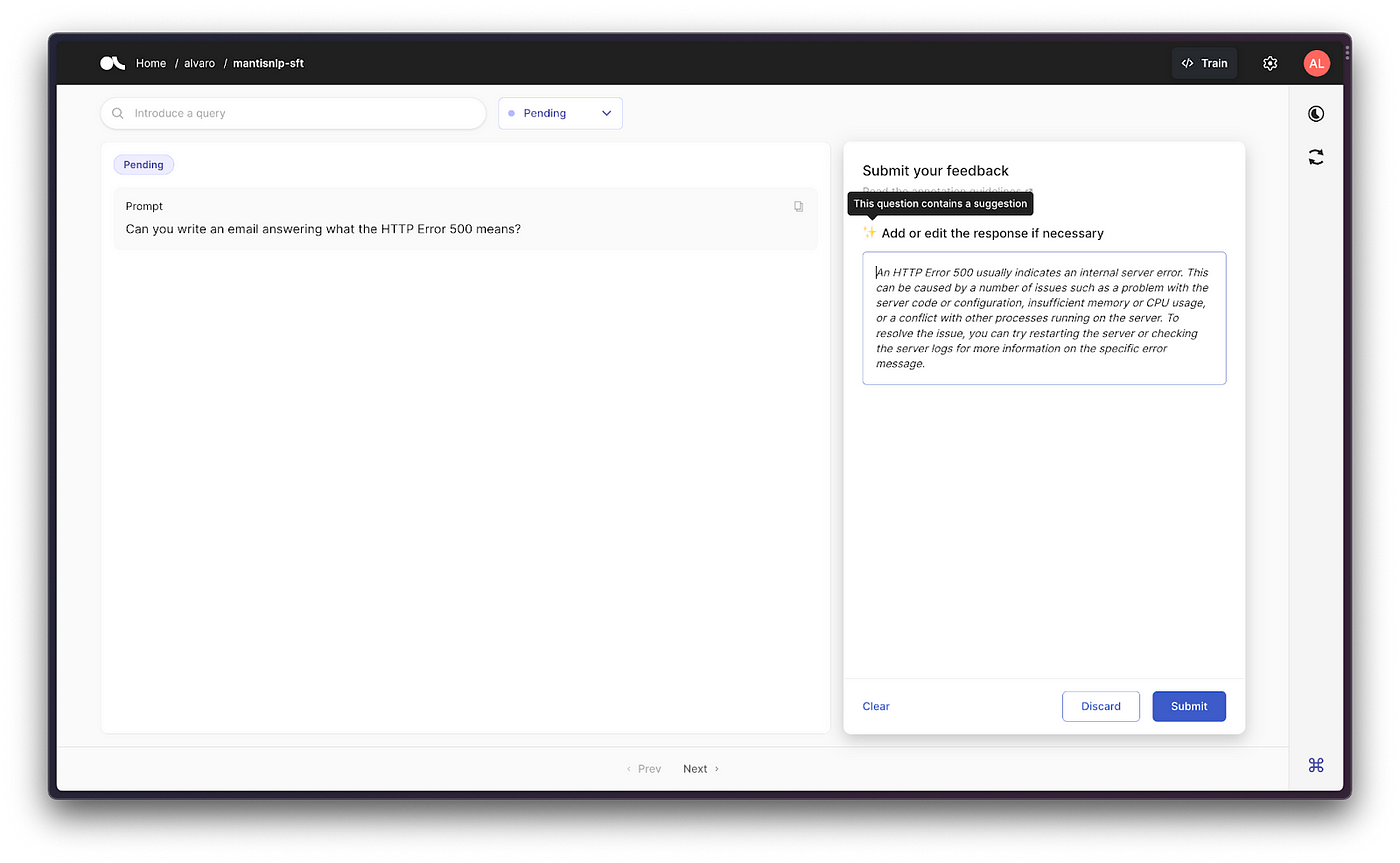
Once the whole dataset has been annotated, or once we’re happy with the annotation (you have some tips on our Distributed Workload blog post), we can already download the FeedbackDataset from Argilla, and format it as we want to later on use it for supervised fine-tuning for instruction-following.
In the blog post Bringing LLM Fine-Tuning and RLHF to Everyone [2] we describe more in detail how to use Argilla for carrying out supervised fine-tuning.
Want to know more?
This is the first entry of a series of blog posts dedicated to alternatives to RLHF. The second post of the series can be found here.
Argilla and Mantis NLP teams are happy to help in any question you may have about preparation steps for training a LLM using Supervised fine-tuning, Reinforcement Learning or Direct Preference Optimization.
All the data curation steps are currently supported by Argilla’s Data Platform for LLM, and from Mantis NLP we offer end-to-end support of the whole process.


