
Through months of fun teamwork and learning from the community, we are thrilled to share our biggest feature to date: Argilla Feedback.
Argilla Feedback is completely open-source and the first of its kind at the enterprise level. With its unique focus on scalable human feedback collection, Argilla Feedback is designed to boost the performance and safety of Large Language Models (LLMs).
In recent months, interest in applications powered by LLMs has skyrocketed. Yet, this excitement has been tempered by reality checks underlining the critical role of evaluation, alignment, data quality, and human feedback.
At Argilla, we believe that rigorous evaluation and human feeedback are indispensable for transitioning from LLM experiments and proofs-of-concept to real-world applications.
When it comes to deploying safe and reliable software solutions, there are few shortcuts, and this holds true for LLMs. However, there is a notable distinction: for LLMs, the primary source of reliability, safety, and accuracy is data.
After training their latest model, OpenAI dedicated several months to refine its safety and alignment before publicly releasing ChatGPT. The global success of ChatGPT heavily leaned on human feedback for model alignment and safety, which illustrates the crucial role this approach plays in successful AI deployment.
Perhaps you assume only a handful of companies have the resources for this. Yet, there's encouraging news: open-source foundation models are growing more powerful every day, and even small quantities of high-quality, expert-curated data can make LLM accurately follow instructions. So, unless you're poised to launch the next ChatGPT competitor, incorporating human feedback for specific domains is within reach and Argilla is your key to deploying LLM use cases, safely and effectively. Eager to understand why? Read on to discover more!
You can add unlimited users to Argilla so it can be used to seamlessly distribute the workload among hundreds of labelers or experts within your organization. Similar efforts include Dolly from Databricks or OpenAssistant. If you’d like help setting up such an effort, reach out to us and we’ll gladly help out.
Argilla Feedback UI: Rate Falcon-7b Responses to Dolly Dataset Prompts.
Argilla Feedback in a nutshell
Argilla Feedback is purpose-built to support customized and multi-aspect feedback in LLM projects. Serving as a critical solution for fine-tuning and Reinforcement Learning from Human Feedback (RLHF), Argilla Feedback provides a flexible platform for the evaluation, monitoring, and fine-tuning tailored to enterprise use cases.
Argilla Feedback boosts LLMs use cases through:
LLM Monitoring and Evaluation: This process assesses LLM projects by collecting both human and machine feedback. Key to this is Argilla's integration with 🦜🔗 LangChain, which ensures continuous feedback collection for LLM applications.
Collection of Demonstration Data: It facilitates the gathering of human-guided examples, necessary for supervised fine-tuning and instruction-tuning.
Collection of Comparison Data: It plays a significant role in collecting comparison data to train reward models, a crucial component of LLM evaluation and RLHF.
Reinforcement Learning: It assists in crafting and selecting prompts for the reinforcement learning stage of RLHF
Custom LLMs. We think language models will be fine-tuned in-house and tailored to the requirements of enterprise use cases. To achieve this you need to think about data management and curation as an essential component of the MLOps (or should we say LLMOps) stack.
Throughout these phases, Argilla Feedback streamlines the process of collecting both human and machine feedback, improving the efficiency of LLM refinement and evaluation. The figure below visualizes the key stages in training and fine-tuning LLMs. It highlights the data and expected outcomes at each stage, with particular emphasis on points where human feedback is incorporated.
 LLM development stages, pioneered by the InstructGPT paper, leading to ChatGPT. This figure is adapted from Chip Huyen’s brilliant post “RLHF: Reinforcement Learning from Human Feedback”
LLM development stages, pioneered by the InstructGPT paper, leading to ChatGPT. This figure is adapted from Chip Huyen’s brilliant post “RLHF: Reinforcement Learning from Human Feedback”
Domain Expertise vs Outsourcing. In Argilla, the process of data labeling and curation is not a single event but an iterative component of the ML lifecycle, setting it apart from traditional data labeling platforms. Argilla integrates into the MLOps stack, using feedback loops for continuous data and model refinement. Given the current complexity of LLM feedback, organizations are increasingly leveraging their own internal knowledge and expertise instead of outsourcing training sets to data labeling services. Argilla supports this shift effectively.
Read on as we detail how Argilla Feedback works, using two example use cases: supervised fine-tuning and reward modelling.
A note to current Argilla users - Argilla Feedback is a new task, fully integrated with the Argilla platform. If you know Argilla already, you can think of Argilla Feedback as a supercharged version of the things our users already love. In fact, it sets the stage for Argilla 2.0, which will integrate other tasks like Text Classification and Token Classification in a more flexible and powerful manner.
Supervised fine-tuning
The importance of demonstration data - prompts and demonstrations - is paramount for improving LLMs. This data aids in supervised fine-tuning, also known as instruction-tuning or behavior cloning, where models learn to respond to instructions based on human examples.
Quality over quantity. Recent research suggests that a dataset of 1,000-2,000 diverse and consistent examples can go a long way in improving instruction-following abilities and response style, surpassing the need for larger demonstration sets used by models like InstructGPT and Dolly.
To visualize the desired effect of supervised fine-tuning, let's see two examples generated by LLMs. First, the model Falcon-7B is not fine-tuned for the following instructions. We're using "Email:" at the end of the prompt to nudge the model into writing an email, but it's still not giving us the results we want:
| Prompt | Completion |
|---|---|
| Write a follow-up for a sales email. Email: | I was just curious if you had any questions about the project I discussed with you on the phone yesterday. Please let me know if I can help you with anything else, or any further details that will help you move forward with your project. Thanks again for your time, and have a great weekend, -Sarah |
And the same model after instruction-tuning, the Falcon-7B-instruct model:
| Prompt | Completion |
|---|---|
| Write a follow-up for a sales email | Dear Customer Name, Thank you for purchasing Product Name from us last week. We hope you have been enjoying using it! If you have any questions or feedback about your purchase, please do not hesitate to let us know. We are always happy to help. Best regards, Sales Team |
The steps to build this workflow are: configure the dataset to ask for completions, add records, gathering feedback from labelers, prepare the dataset, and fine-tuning the LLM. Read on to learn more about each step and see below a visual representation.
 Human-in-the-loop workflow for demonstration data collection and SFT
Human-in-the-loop workflow for demonstration data collection and SFT
Configure the dataset
First, we need to configure a dataset. Argilla datasets allow you to mix different questions for labelers to answer. In this case, we want to collect demonstrations from our labelers.
With Argilla's Python SDK, you set up a TextQuestion for your labelers to write the demonstration and a TextField to show them a prompt. You can set up the dataset with the following code snippet:
import argilla as rgquestions = [ rg.TextQuestion( name="completion", title="Please write an accurate, helpful, and harmless response to the prompt", required=True, )]fields = [ rg.TextField(name="prompt", required=True),]dataset = rg.FeedbackDataset( guidelines="Please, read the prompt carefully and write a response", questions=questions, fields=fields)Add records
Argilla Datasets are composed of records. A record is a data point that can be labeled by one or more labelers. In the case of supervised fine-tuning our goal is gather human-written responses to prompts. There are many alternatives for collecting prompts, that range from asking labelers to write them to using an open dataset to generating them using an LLM. We cover these different scenarios in detail in the docs. Let's assume we have a dataset with prompts, this is how to build and push the records:
from datasets import load_dataset# This is only for demonstration and assumes you use a HF datasetprompts = load_dataset('your_prompts_dataset', split=["train"])records = [ rg.FeedbackRecord(fields={"prompt": record["prompt"]}) for record in dataset]dataset.add_records(records)# This publishes the dataset and pushes the records into Argilladataset.push_to_argilla(name="my-dataset", workspace="my-workspace")Gathering feedback from labelers
Argilla Feedback allows simultaneous feedback collection from multiple users, enhancing quality control. Each user with dataset access can give feedback. However, when resources are limited, workload distribution among various labelers is recommended. This strategy entails assigning each labeler a subset of the total records. In the docs, we provide detailed instructions for setting up these workload distribution options effectively.
Prepare dataset and fine-tune the LLM
After collecting feedback from labelers, there's two steps left: preparing the dataset, including the resolution and aggregation of responses from multiple labelers, and fine-tune the LLM.
Argilla's documentation covers several approaches to handle disagreements and merge feedback from multiple labelers. For instruction-tuning, the typical format consists of a prompt, a response, and potentially an optional inputs field (like in the Alpaca and Dolly datasets).
For fine-tuning, you can use Hugging Face AutoTrain, peft/Lora, and many others like MosaicML, or Lightning. Argilla's documentation covers several approaches in detail.
Now, let's move on to the next use case: reward modeling.
Reward modelling
Collecting comparison data to train a reward model is a crucial part of RLHF and LLM evaluation. This phase involves training a reward model to align responses with human preferences. Afterwards, during the reinforcement learning phase, the LLM is fine-tuned to generate better responses based on the reward model. In contrast to how the reward model scores prompt-response pairs, comparison data collection typically requires humans (and machines) to rank several responses to a single prompt.
The steps to build this workflow are: configure the dataset to ask for comparisons, add records, gathering feedback, prepare the dataset, and train the reward model. Read on to learn more about each step and see the figure below for a visual representation.
 Human-in-the-loop workflow for comparison data collection and reward modelling
Human-in-the-loop workflow for comparison data collection and reward modelling
Human Preference Optimization. The recent study, "Direct Preference Optimization: Your Language Model is Secretly a Reward Model" proposes the promising possibility of using comparison data directly, eliminating the need for a reward model. Nevertheless, the collection of comparison data continues to be crucial for steering LLMs.
Configure the dataset
Let's start by creating a dataset for collecting ranked responses. With Argilla's Python SDK, you set up a RatingQuestion for your labelers to answer, an optional TextQuestion to write a corrected response, and a TextField to present them with a prompt. You can set up the dataset with the following code snippet:
import argilla as rgquestions = [ rg.RatingQuestion( name="response_ranking", title="Rank the responses\n1: first response is better,\n 2: second response is better,\n3: both are equal", required=True, values=[1, 2,3] ), rg.TextQuestion( name="correct_response", title="If none of the responses are helpful and correct, provide the response", required=False ),]fields = [ rg.TextField(name="prompt", required=True), rg.TextField(name="response-1", required=True), rg.TextField(name="response-2", required=True)]dataset = rg.FeedbackDataset( guidelines="Please, read the prompt carefully and...", questions=questions, fields=fields)This will configure the following UI. Note that Argilla datasets are highly configurable so you can add any fields and questions you need for your use case:
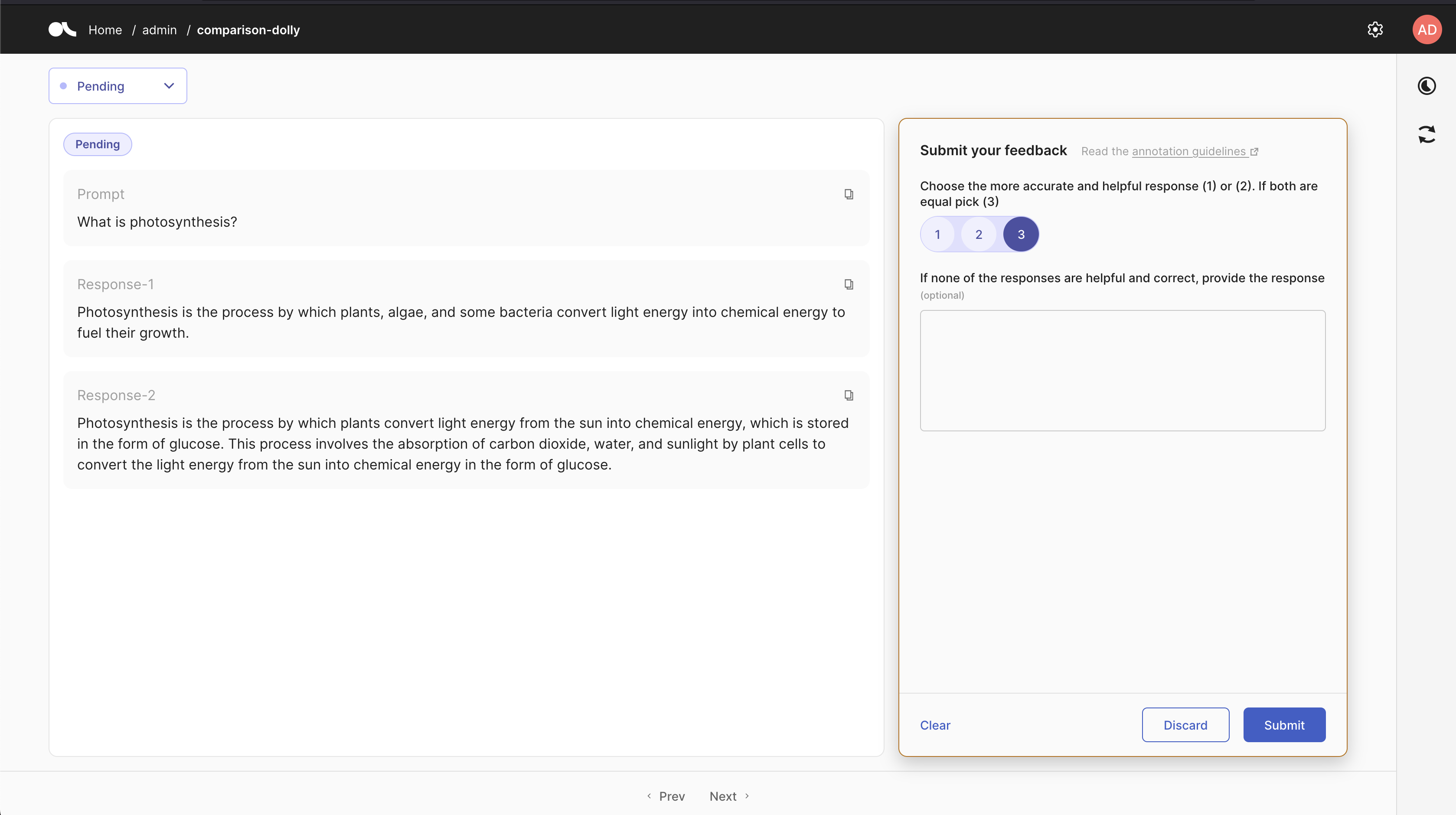 Argilla UI for this custom use case with Falcon-7B generations for comparison data collection
Argilla UI for this custom use case with Falcon-7B generations for comparison data collection
This example involves ranking two responses per prompt, but you can modify it to handle more. Keep an eye out for the RankingQuestion in future Argilla updates, which is designed to optimize this process. You can follow the progress on GitHub
Add records
Now, let's move on to the next step: adding records to the dataset and making them available for labelers. Each record will include a prompt and two generated responses. These records will be shown to labelers in the Argilla user interface, where they will be asked to rank the two responses. During this stage, it's crucial to consider how to generate the responses effectively to ensure the resulting LLM achieves optimal quality and diversity.
To generate the responses, you can employ a pre-trained LLM that has been fine-tuned on a previous dataset. Various strategies can be used, such as generating multiple responses and selecting two of them, or generating two responses with different parameters, such as temperature settings.
If you have a instruction-tuned LLM in mind, here's an example using the instruction-following model Falcon-7B-instruct to generate the responses and create Argilla records:
# Load the model and tokenizermodel = AutoModelForCausalLM.from_pretrained("tiiuae/falcon-7b-instruct")tokenizer = AutoTokenizer.from_pretrained("tiiuae/falcon-7b-instruct")# Create a pipeline for text generationgen_pipeline = pipeline( "text-generation", model=model, tokenizer=tokenizer, torch_dtype=torch.bfloat16, device_map="auto",)# Load your dataset of promptsprompts = load_dataset("your_prompts_dataset", split=["train"])records = []for record in prompts: prompt = record["prompt"] # Generate two responses in one call outputs = gen_pipeline( prompt, max_length=100, do_sample=True, top_k=10, num_return_sequences=2, eos_token_id=tokenizer.eos_token_id, ) responses = [output["generated_text"] for output in outputs] record = rg.FeedbackRecord(fields={"prompt": prompt, "response 1": responses[0], "response 2": responses[1]}) records.append(record)# Add records to the datasetdataset.add_records(records)# This publishes the dataset and pushes the records into Argilladataset.push_to_argilla(name="my-dataset", workspace="my-workspace")Prepare the dataset and train a reward model
In the docs, we cover how to prepare the data in this format for training a Reward Model using the trl framework. Let's look at the code to train a Reward Model using this dataset created by the Argilla team. This model uses comparison data created with the Dolly dataset from Databricks and Falcon-7B-Instruct, a small version of the current strongest open-source LLM model as of June 1st 🤗.
from transformers import ( AutoModelForSequenceClassification, AutoTokenizer, TrainingArguments,)from trl import RewardTrainerfrom datasets import load_datasetdataset = load_dataset("argilla/dolly-curated-comparison-falcon-7b-instruct", split="train")model_name = "distilroberta-base"model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=1)tokenizer = AutoTokenizer.from_pretrained(model_name)if tokenizer.pad_token is None: tokenizer.pad_token = tokenizer.eos_token model.config.pad_token_id = model.config.eos_token_iddef formatting_func(examples): kwargs = {"padding": "max_length", "truncation": True, "max_length": 512, "return_tensors": "pt"} # Assuming original human response is preferred to Falcon's chosen_response = examples["original_response"] rejected_response = examples["response-1"] prompt = examples["prompt"] tokens_chosen = tokenizer.encode_plus(prompt, chosen_response, **kwargs) tokens_rejected = tokenizer.encode_plus(prompt, rejected_response, **kwargs) return { "input_ids_chosen": tokens_chosen["input_ids"][0], "attention_mask_chosen": tokens_chosen["attention_mask"][0], "input_ids_rejected": tokens_rejected["input_ids"][0], "attention_mask_rejected": tokens_rejected["attention_mask"][0] }formatted_dataset = dataset.map(formatting_func)trainer = RewardTrainer( model=model, args=TrainingArguments("output_dir"), tokenizer=tokenizer, train_dataset=formatted_dataset)trainer.train()After running this step, we have a reward model ready to use for RLHF and LLM evaluation!
If you want to know more about the resulting reward model and how it’s been built, it’s 100% open-source and available on the Hugging Face Hub.
Below you can find the score of some examples (remember the RM has been trained to prefer the original response):
| Prompt | Original Response | Response-1 | Score Original | Score Response-1 |
|---|---|---|---|---|
| What is Depreciation | Depreciation is the drop in value of an asset due to wear and tear, age and obsolescence (going out of date) as recorded in an organization's financial records. | What is Depreciation – 10 Important Facts to Know? When a business buys a new asset, the purchase price of that asset is depreciated over time to reflect its usage and eventual obsolescence. Depreciation expense can be a tax deductible expense and is usually a non-cash expense reported on a company’s income statement and balance sheet. The amount of... | 1.9764 | -9.01173 |
| What do you know about the city of Aberdeen in Scotland? | Aberdeen is a city located in the North East of Scotland. As of 2020 it had a population of 200,000 people and is the third largest city in Scotland, behind Edinburgh (435,000) and Glasgow (610,000). Aberdeen has been referred to as "The Silver City" due to the high number of buildings in the city constructed of Granite from the local quarry, which may sparkle on the rare occasion that the sunlight hits the buildings. Since the 1960's the city's economy has largely revolved around Oil & Gas due to its proximity to the North Sea Oil discovery. Aberdeen has two universities; the University of Aberdeen and Robert Gordon University. Notable people who have been associated with Aberdeen include singer Annie Lennox, golfer Paul Lawrie and architect Archibald "Archie" Simpson. | Aberdeen, the city in which I've lived for the past 4 years, is the 3rd largest city in Scotland with a population of around 700,000. It has a long history, with evidence of human occupation dating back around 5000 years. The city is home to the famous "Rock" of Aberdeen (which is in fact the city itself) as well as several universities and is one of the biggest financial centers in the country. | 7.03729 | -6.4728 |
What’s next?
This blog post only scratches the surface of what's possible with Argilla. We're thrilled to play a key role in the evolution of open-source LLMs. Our roadmap includes integrating already-loved Argilla features like suggestions (now known as predictions) from multiple models and rules, active learning for SFT and reward modeling, vector search, and weak supervision into this new paradigm.
Check out the Argilla Feedback Data Model docs for a sneak peek at upcoming features (see below figure).
 Argilla Feedback Data Model and upcoming features
Argilla Feedback Data Model and upcoming features
Stay tuned for more updates! If you need assistance setting up human-in-the-loop workflows for your LLM use cases, reach out to us and we’ll gladly help out.
Get started with Argilla Feedback
You can self-host Argilla using one of the many deployment options, sign-up for our upcoming Argilla Cloud version, or launch an Argilla Space on the Hugging Face with this one-click deployment button:

Conceptual Guides: An extensive overview about how to use Argilla for LLM data collection, fine-tuning, and RLHF.
How-to-Guides: A practical, hands-on introduction to Argilla Feedback.


