
NLP Glossary: Understand the key terms
June 8, 2022
Not so long ago, Natural Language Processing (NLP) was only contemplated in the research world. Today it is becoming a key component in companies of various sizes and sectors, connecting different profiles.
NLP is no longer reserved only for researchers and data engineers. Roles and job titles are increasing under the data science umbrella: data linguists, business analysts, MLOps engineers, data annotation specialists, product managers… (to name just a few) and they all have to understand each other around a common language.
This glossary aims at putting all professionals on the same page. To learn further and reinforce your understanding, many definitions are linked to guides, tutorials, and posts related to Rubrix.
1. Accuracy
The accuracy of a model refers to the percentage of correct predictions it makes on a given dataset. It is a convenient single-digit metric to compare models with, but it rarely gives you the full picture of a model’s performance. Furthermore, for many NLP tasks this metric is not very useful since the “correctness” of a prediction is more nuanced. In text summarization, for example, the summary generated by the model can be more or less accurate.
Check Rubrix’s metrics guide for more practical metrics that help you to analyze your model’s performance.
2. Active Learning
Active learning is a special case of supervised machine learning, in which a user interactively aids the learning process by providing labels to new examples of a dataset without annotations. It is normally an iterative process in which the learning algorithm determines the most valuable examples and actively queries the user for the respective labels. Since the learner chooses the examples, it often requires far less training data to achieve the same performance as with normal supervised learning.
Rubrix has a tutorial that shows how to build a spam filter by applying active learning.
3. Annotations
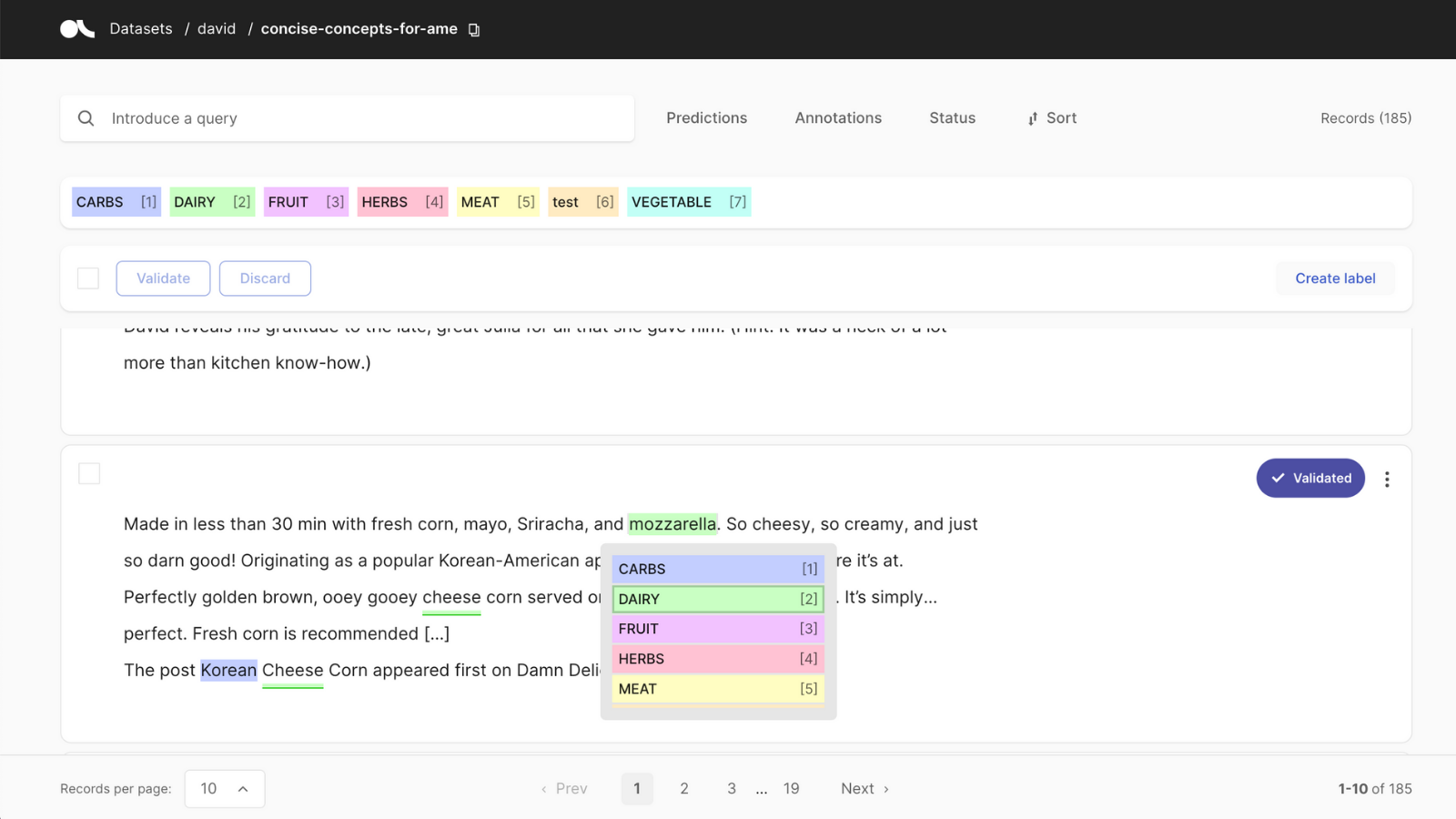
Most NLP models today are trained via supervised learning. For training such models we need input-output pairs that will serve as training examples for the model. The output part of such pairs is often referred to as labels or annotations since it is normally a human, that labels or annotates the corresponding input text. This is usually a manual process carried out by individuals, although techniques such as active learning or weak supervision can reduce this manual effort.
The quality of NLP models is directly related to the quality of the training data. This makes the annotation task crucial for the success of a project. Rubrix's annotate mode tries to make this process as easy and effortless as possible.
4. Dataset
In NLP, the term dataset broadly refers to data that is meant to be used for creating or evaluating a predictive model. For most NLP tasks the dataset has to have features, which is usually the text you want to process, and labels, which are usually annotations made by humans. It is common to divide a dataset into a training set, a validation set, and a test set. They are used to train the model, validate the model, and compare different models, respectively.
In Rubrix, a dataset is a collection of records, each one containing an input text. Optionally they can also carry annotations, predictions, and some metadata. These datasets can come from social media, reviews (i.e. IMDB), text databases, or news, just to give some examples.
5. F1 Score
The F1-score (or F1-measure, or simply F1) is the harmonic mean of the precision and recall. Its averaged value over all classes is a convenient single-digit metric to compare models with, but it rarely gives you the full picture of a model’s performance. Its maximum value is 1 indicating perfect precision and recall. Its minimum value is 0 when either the precision or the recall is 0.
The F1-score is often stated together with the Precision and Recall metric. See accuracy for limitations of these metrics that are based on a binary notion of correctness. Also, check our Metrics blog post for a practical guide on how to interpret some of these metrics with the help of Rubrix.
6. Human-in-the-loop
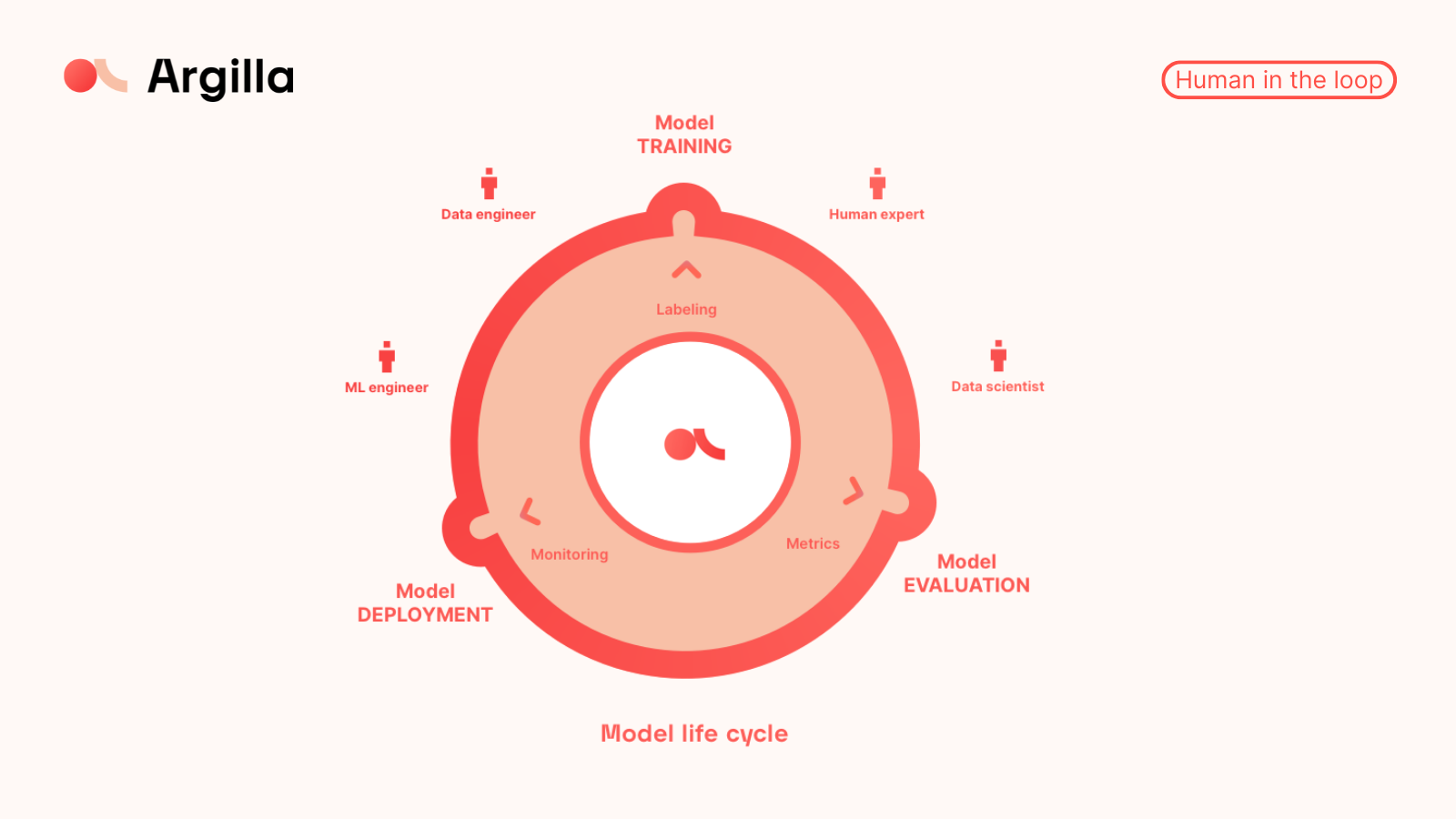
Human-in-the-loop machine learning is the combination of human intelligence and artificial intelligence to take advantage of both and create powerful and effective models. When we talk about a human-in-the-loop tool, we refer to the interaction of humans in an NLP tool such as Rubrix. This approach can maximize the performance of a tool and make us continuously learn and improve models and procedures, as we can annotate, build and improve models in direct interaction with a machine (the tool itself).
7. MLOps
Machine Learning Operations (MLOps), is an extension of the DevOps methodology and practice. DevOps ("DEVelopment+OPerationS"), describes the combination of people, processes, and technologies involved in the software creation lifecycle. MLOps broadens the concept by including the concepts of machine learning processes and data science, and its use helps in building quality models, as well as in data governance and optimization.
8. Named Entity Recognition (NER)

NER is a text analysis technique used in NLP. It allows to automatically extract entities (one or more words that identify a concept) from a text and classify them based on predefined categories or labels. NER systems can be based on machine learning models, rules, or dictionaries - most commonly, they are a combination of these techniques.
Click here to read a very interesting article we wrote after carrying out a super cool NER experiment.
9. Natural Language Inference (NLI)

This very common NLP task is quite similar to text classification, but its purpose is different. In Natural Language Inference (NLI), the model receives a premise and a hypothesis, and it must figure out if the hypothesis is true (entailment), false (contradiction), or undetermined (neutral) given the premise.
10. NLP tasks
NLP tasks are typically easy for humans to solve but tend to be difficult for machines. There is a wide variety of tasks that can be tackled via NLP and in this glossary, we explain some of them, like sentiment analysis, NER, NLI, and text summarization.
For a more complete list of tasks, you can have a look at our comprehensive task examples.
11. Precision
When evaluating a model, the precision of a class (label) is the fraction of its correct predictions on a given dataset. That is if a model predicts class “A” 10 times, and 9 of those 10 predictions are correct, the precision would be 0.9. One can average the precision of all classes by simply adding them up and divide them by the number of classes, which is known as macro average. A weighted average of all classes by their number of predictions is known as micro average.
The precision is often stated together with the Recall metric and the F1 score. See accuracy for limitations of these metrics that are based on a binary notion of correctness.
12. Predictions
Once a model is trained, we usually refer to its output, given some input, as predictions. Predictions are often stated as percentages that reflect the confidence of the model in its decision. For text classification tasks, for example, the model would output a percentage for each of the classes (labels) of the task given an input text. For token classification tasks, the model would output such percentages for each token in the input text.
Exploring single predictions of your model almost always gives you additional insights about your model performance, compared to relying solely on single-number metrics. Predictions can also be used to pre-annotate datasets to help with manual annotation workflows. For a practical example of this approach, check our finetuning tutorial.
13. Recall
When evaluating a model, the recall of a class (label) is the fraction of its correct detections on a given dataset. That is if there are 10 examples of class “A” in the dataset, and the model detects 9 of those 10 examples correctly, the recall would be 0.9. One can average the recall of all classes by simply adding them up and dividing them by the number of classes, which is known as macro average. A weighted average of all classes by their number of examples is known as micro average.
The recall is often stated together with the Precision metric and the F1 score. See accuracy for limitations of these metrics that are based on a binary notion of correctness.
14. Sentiment Analysis
With this text classification technique, we can get our models to be able to detect the polarity of the input - categories like positive, negative, or neutral are often used. The use of this technique is common in the business world, for analyzing social media and the general feedback of their customers. It is also useful for analyzing emotions, opinions or choices in surveys, market studies, or reviews, to name a few.
This is an example focused on analyzing the sentiment of banking user requests.
15. Text2Text

Text2Text tasks are text generation tasks where the model receives an input (text) and outputs a sequence of tokens. Examples of such tasks are machine translation, text summarization, or paraphrase generation, being machine translation the most common task of them all. In this case, the input is a sequence of text that is aimed to be translated into one or more different languages (the output).
16. Text Classification
Text classification tasks focus on properly categorizing a sentence or a document into one or more groups. These categories will depend on the topic, the dataset, and the specific task. For instance, you might want to analyze the sentiment (positive, negative, neutral) of a dataset containing film reviews - this would be a sentiment analysis task. Some other well-known tasks are Natural Language Inference, multi-label text classification, or semantic textual similarity, to name a few.
Rubrix is adapted to these tasks and provides interesting features, such as metrics or the define rules mode. Click here to read a very interesting text classification tutorial.
17. Text Summarization
In NLP tasks, text summarization is the process of summarizing large, or medium amounts of information (texts) in order to get straight to the data, or to simply read them quickly. With this task, important information is extracted and broken into paragraphs or sentences, without omitting critical information and providing a concise but complete summary.
18. Tokens/Tokenization
Tokenization is part of the text pre-processing, this is, preparing and adapting the text to an NLP task. In this preprocessing step the input text is divided into units of text that are referred to as tokens. Tokens often correspond to words, but can also correspond to smaller units (often called subwords), or even characters.
19. Token Classification
Token classification tasks are aimed to divide the input text into words, or syllables, and assign labels to them. While text classification is focused on classifying the text as a whole, token classification is focused on classifying single tokens. While Named Entity Recognition (NER) is probably the most well-known, part-of-speech tagging or slot filling are also very common tasks.
If you want to know more about this, we recommend this tutorial. NER tasks are super easy with Rubrix!
20. Weak Supervision
Weak supervision is a branch of machine learning based on getting large amounts of training data with lower-quality labels, instead of using hand-labeled datasets, which can be costly or impractical. The noisy labels are often obtained by exploiting the heuristics of a dataset expressed as rules. Special label models can take into account some of the label noise, and output denoised weak labels that can be used to train a model often referred to as the downstream model.
Rubrix extensively supports weak supervision workflows as showcased in our dedicated tutorials.
21. Zero-Shot Learning
Zero-shot learning is a problem setup, where a machine learning model must predict classes it has not seen at training time. In zero-shot text classification, for example, an already trained model is presented with an input text and a list of classes it must classify the text with. Zero-shot models usually perform significantly worse when compared to dedicated trained models, but are more versatile.
They can be used to pre-annotate data, as shown in our zero-shot NER tutorial.


