
A few months ago, we introduced distilabel, a Python library for synthetic data generation and AI feedback using LLMs. At the time, we started with a simple approach, where the user could generate synthetic data using a single LLM called generator and then label it using another LLM called labeller. This approach was useful for many scenarios, especially generating preference datasets. Thanks to this first version, we've generated and openly shared impactful datasets like argilla/distilabel-capybara-dpo-7k-binarized, argilla/OpenHermesPreferences, argilla/distilabel-intel-orca-dpo-pairs, among others, that have been used to train several SOTA models. We also saw an increasing adoption of distilabel in the community, with cool community projects such as davanstrien/haiku.
Having that said, we are aware that the previous implementation was not suitable for more complex synthetic data generation pipelines, like DEITA, which requires running several LLMs and more complex steps. On top of that, we wanted to make the project less complex to scale and easier for the community to contribute. The decision was clear: we needed to rewrite the library from scratch to address this and make it more extensible, maintainable, and scalable.
Today, we’re happy to announce distilabel 1.0.0, a new version of the library that brings a new architecture allowing to build complex data processing pipelines with LLMs, and with the hope to make it easier for the community to create and share synthetic data generation pipelines.

Pipelines, Steps, Tasks and LLMs
This new version of distilabel allows to build Pipelines with any number of Steps or Tasks, that can be connected between, so the output of one step or task is fed as input to another. It's no longer about one generator and one labeller, but about a series of steps that can be chained together to build complex data processing pipelines with LLMs.
A Step is a more general node relying on a base class that does not require an LLM or model to be used. The input of each Step is a batch of data, containing a list of dictionaries, where each dictionary represents a row of the dataset, and the keys are the column names. An Step then can:
- Add or remove keys from the dictionaries to modify the columns of the final dataset.
- Filter out dictionaries to remove rows from the dataset.
- Add new dictionaries to the batch to add new rows to the dataset.
In addition, a Step offers a simple life cycle, exposing a load method that can be used to create the necessary resources that will be used in the process method, where the actual data processing is done. Finally, each Step can define a list of runtime parameters that can be used to configure the behavior of the Step for each pipeline execution.
Building on this basic idea, distilabel offers two additional kind of steps apart from the normal Step which are the GeneratorStep and the GlobalStep.
GeneratorSteps are nodes that loads data from a source (for example, from a dataset from the Hugging Face Hub) or generates new data (for example, using SelfInstruct and a list of topics), therefore they are the starting nodes of the pipeline and do not require any incoming edges.
On the other hand, GlobalSteps works exactly the same as the Steps but they receive all the data from the previous steps all at once, allowing to aggregate data from previous steps or to perform operations that require the full dataset, like filtering out rows that are repeated.
Continuing on from the Step concept, we have evolved the Task concept from the previous version, which is now a Step that knows how to use an LLM to perform a specific task such as text generation, evolving instructions or responses, judging the quality of a text, etc.
Pipeline execution
For this new version, we've also changed the way the pipelines are executed. In the previous version, the execution was sequential, meaning that the generator was executed first, and then the labeller was executed.
Now, the execution is parallel using several processes, each one executing a different step of the pipeline. When the subprocess is created, it will execued the load method of the step, and then it will start processing batches received from an input queue. The resulting batches will be sent back to the main process through an output queue, where they will be distributed to the next steps in the pipeline.
For this first version, we have decided to use the multiprocessing module from the Python standard library to manage the subprocesses and to have a single node pipeline execution, which is enough for most of the cases. Having that said, we gave a lot of thought to the design of the architecture to add support for distributed execution in the future, using libraries like Ray.
Sharing pipelines
One of the main goals of this new version of distilabel is to make it easier for the community to create and share synthetic data generation pipelines. To achieve this, we have added a new feature that allows to serialize a pipeline to a JSON or YAML file, and to load it back from the file, allowing to tweak the runtime parameters of the pipeline and to run it again. In addition, pushing the resulting dataset to the Hugging Face Hub will automatically push the pipeline to the Hub as well, and add a nice description of the pipeline to the dataset card, making it easier to reexecute the pipeline in the future.
and if you are you not a script person 👨🏻💻? ...
No worries, we got you covered! We have also added a CLI that allows to get the info of a pipeline from a file or URL:
distilabel pipeline info --config "https://huggingface.co/datasets/distilabel-internal-testing/instruction-dataset-with-llama3/raw/main/pipeline.yaml"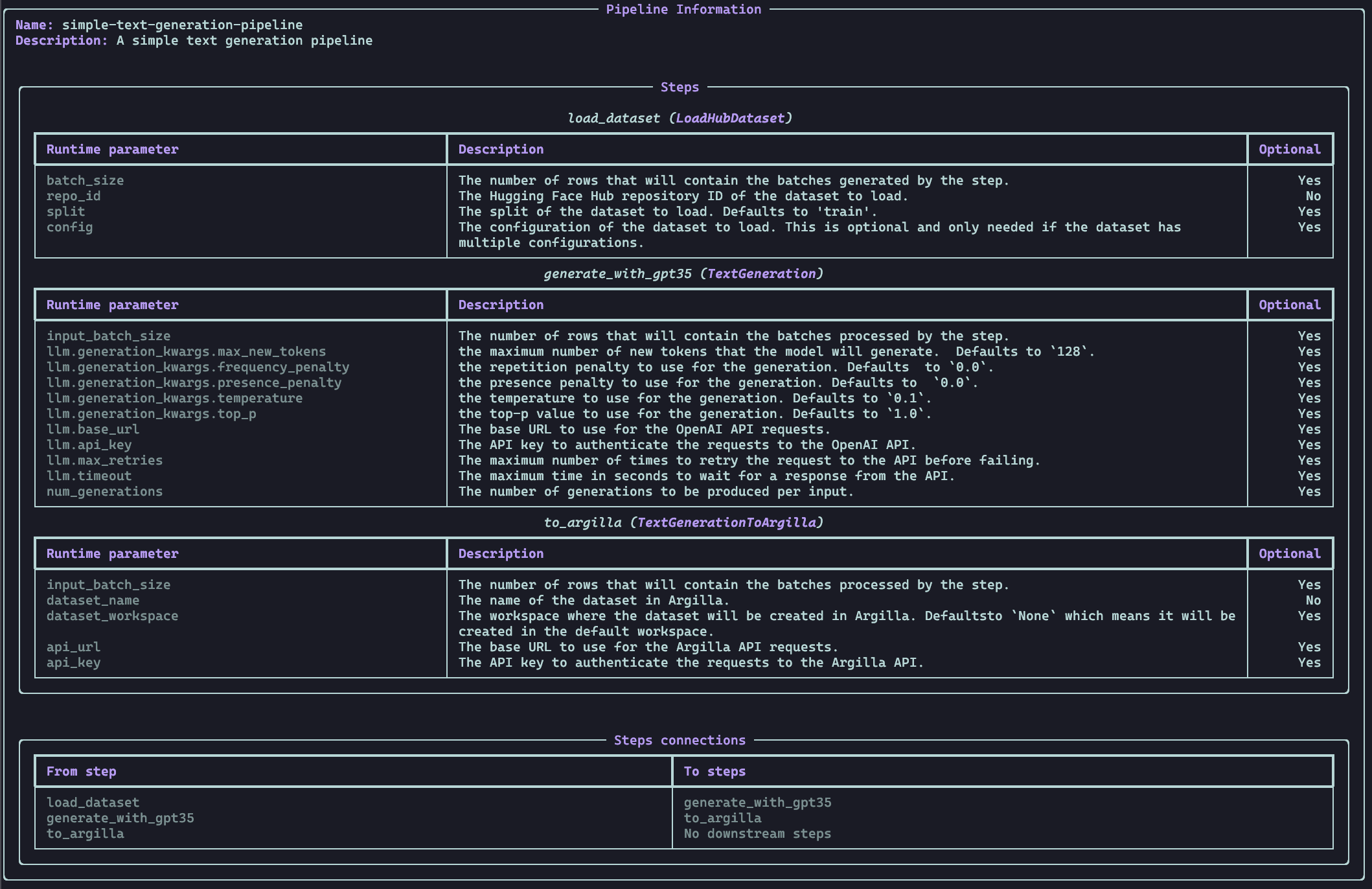
and to run a pipeline from a file or URL:
distilabel pipeline run --config "https://huggingface.co/datasets/distilabel-internal-testing/instruction-dataset-with-llama3/raw/main/pipeline.yaml" \ --param load_dataset.repo_id=distilabel-internal-testing/instruction-dataset-mini \ --param load_dataset.split=test \ --param generate_with_llama3.llm.generation_kwargs.max_new_tokens=512 \ --param generate_with_llama3.llm.generation_kwargs.temperature=0.7An overview of the differences
The main differences between the former and the current version are:
| distilabel ≤ 0.6.0 | distilabel ≥ 1.0.0 | |
|---|---|---|
| # of LLMs | 2 at most | From 0 to N (not mandatory to use LLMs) |
| # of Tasks | 2 at most (generator and labeller) | From 1 to N |
| Integrations | OpenAI, vLLM, Llama.cpp, Transformers, Inference Endpoints, Together, Anyscale, Ollama and Vertex AI | Same as before, but also Cohere, Azure OpenAI and LiteLLM |
| Flow | Generator → Labeller | Any → … → Any (where … can be an arbitrary number of tasks) |
| Execution | Sequential | Parallel |
| Ease of contribution | Medium-Hard | Easy |
| Argilla | Integrated on every pipeline | Detached, following a plug and play approach anytime |
| Hierarchy | LLM | Pipeline > Step > Task (> LLM) |
| Syntax | generator and labeller | Arbitrary, defined by the user |
| Approach | Chained Python functions | DAG |
| Sharing | Hard to share pipelines | Easy to share pipelines thanks to the serialization and the CLI |
Former
- Only for
generator-labellerscenarios - Hard to scale / maintain
- Not suitable for most of the synthetic data generation pipelines
from datasets import load_datasetfrom distilabel.llm import OpenAILLMfrom distilabel.pipeline import pipelinefrom distilabel.tasks import TextGenerationTaskdataset = ( load_dataset("HuggingFaceH4/instruction-dataset", split="test[:10]") .remove_columns(["completion", "meta"]) .rename_column("prompt", "input"))task = TextGenerationTask()generator = OpenAILLM(task=task, max_new_tokens=512)pipeline = pipeline("preference", "instruction-following", generator=generator)dataset = pipeline.generate(dataset)Current
- Can have any number of steps of any kind (not only LLMs)
- Is more extensible, maintainable and scalable
- May require more computing for local LLMs as the steps run in parallel
from distilabel.llms import OpenAILLMfrom distilabel.pipeline import Pipelinefrom distilabel.steps import LoadDataFromDictsfrom distilabel.steps.tasks import TextGenerationwith Pipeline() as pipeline: load_dataset = LoadDataFromDicts( name="load_dataset", data=[ { "instruction": "Write a short story about a dragon that saves a princess from a tower.", }, ], ) text_generation = TextGeneration( name="text_generation", llm=OpenAILLM(model="gpt-4"), ) load_dataset.connect(text_generation) ...if __name__ == "__main__": distiset = pipeline.run( parameters={ "text_generation": { "llm": { "generation_kwargs": { "temperature": 0.7, "max_new_tokens": 512, } } }, ... }, ) distiset.push_to_hub( "distilabel-internal-testing/instruction-dataset-mini-with-generations" )So what's next?
You can check distilabel GitHub repository and the documentation to learn more about the new version, and to start creating your own synthetic data generation pipelines.
We hope that this new version of distilabel will make it easier for the community to create and share synthetic data generation pipelines, and that it will help to democratize the use of synthetic data generation and AI feedback. We are excited to see what the community will build with this new version of distilabel, and we are looking forward to your feedback and contributions!


