
🏉 Distribute the workload in Argilla
April 28, 2023
When you're annotating data as a team, you want to make sure that everyone has their own bit to work on, without accidentally duplicating efforts. In this blog post, I'll show you two ways to use old and recent features in Argilla to split up the work in your team, depending on your needs.
Option 1: use record metadata
One possible way to communicate assignments to your team is by adding a field in the record metadata with information on who should be annotating that record. If you’re using Argilla >1.6.0, make sure that this dataset is in a workspace that all the team members can access.
This option is useful if:
- you want to keep a single dataset.
- you want your team members to have access to the whole dataset e.g., to write weak labelling rules based on the annotations of the whole team.
- you want your team members to see the overall progress of the dataset.
- you only need 1 annotation per record.
When your team is ready to start annotating, you just need to ask them to open the dataset and use the Metadata filter in the UI so that they can focus on the records assigned to them.
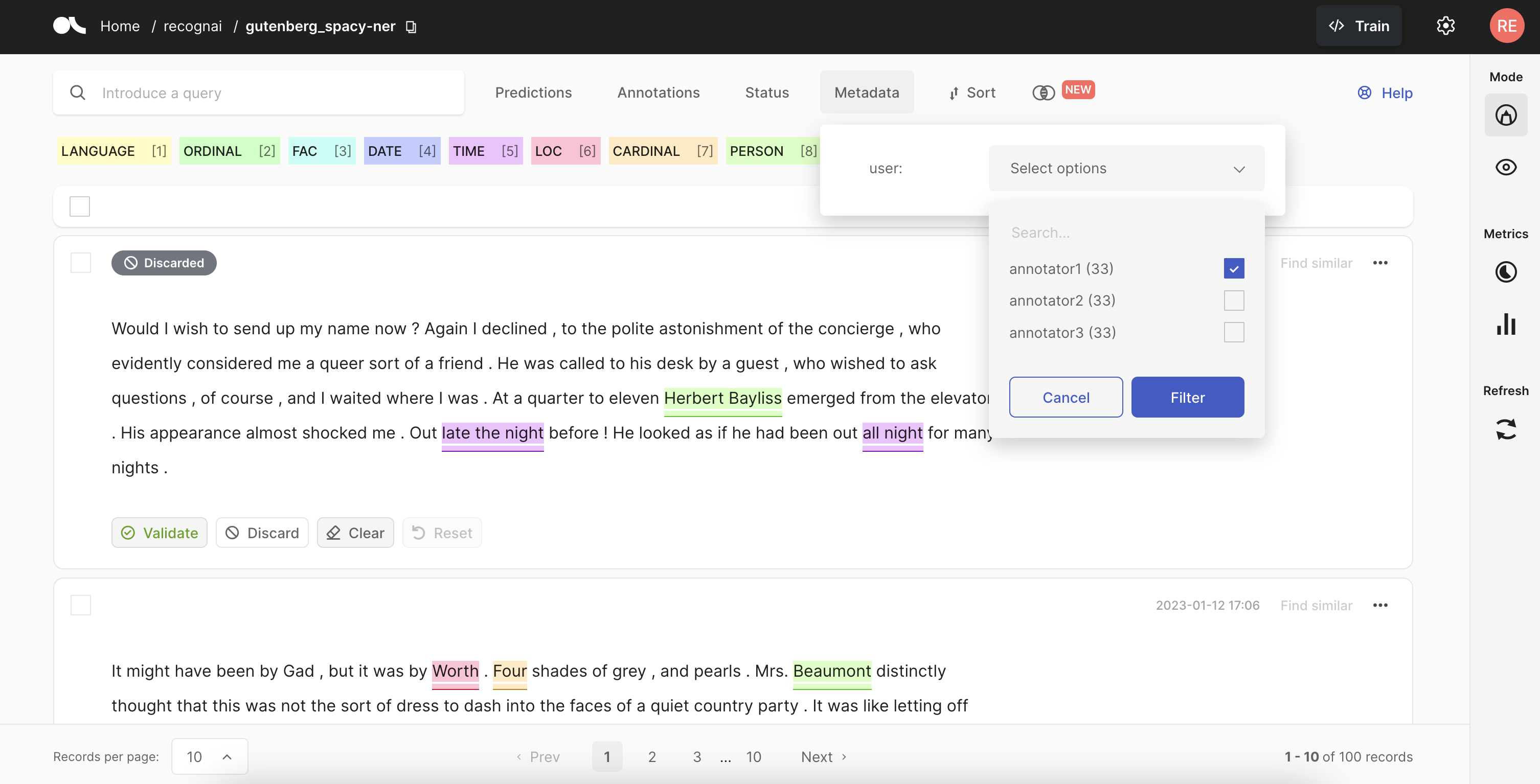 View of the Metadata filter inside the dataset in the Argilla UI
View of the Metadata filter inside the dataset in the Argilla UI
**Note: your team can still use queries and similarity search with this filter on and they will only get records from their split. They will need to turn it off to get records from the whole dataset.
Option 2: split the dataset
Another way to do this is to leverage user roles and workspaces to block the data that each user can access. In this solution, you will need to update Argilla to v1.6.0 and make a split of your dataset for each user. These splits will only have the records assigned to each user and they will be logged as separate datasets in the personal workspace of the corresponding user.
This option is useful if:
- you want each team member to work independently and not see the records and annotations of their teammates, e.g. if you want to measure annotator agreement afterwards.
- you want your team members to see only their individual progress.
- you want to have annotation overlap. If this is the case, we recommend assigning an ID to each record to be able to reconstruct the original dataset in post-processing.
- you don’t mind having a separate dataset for each split.
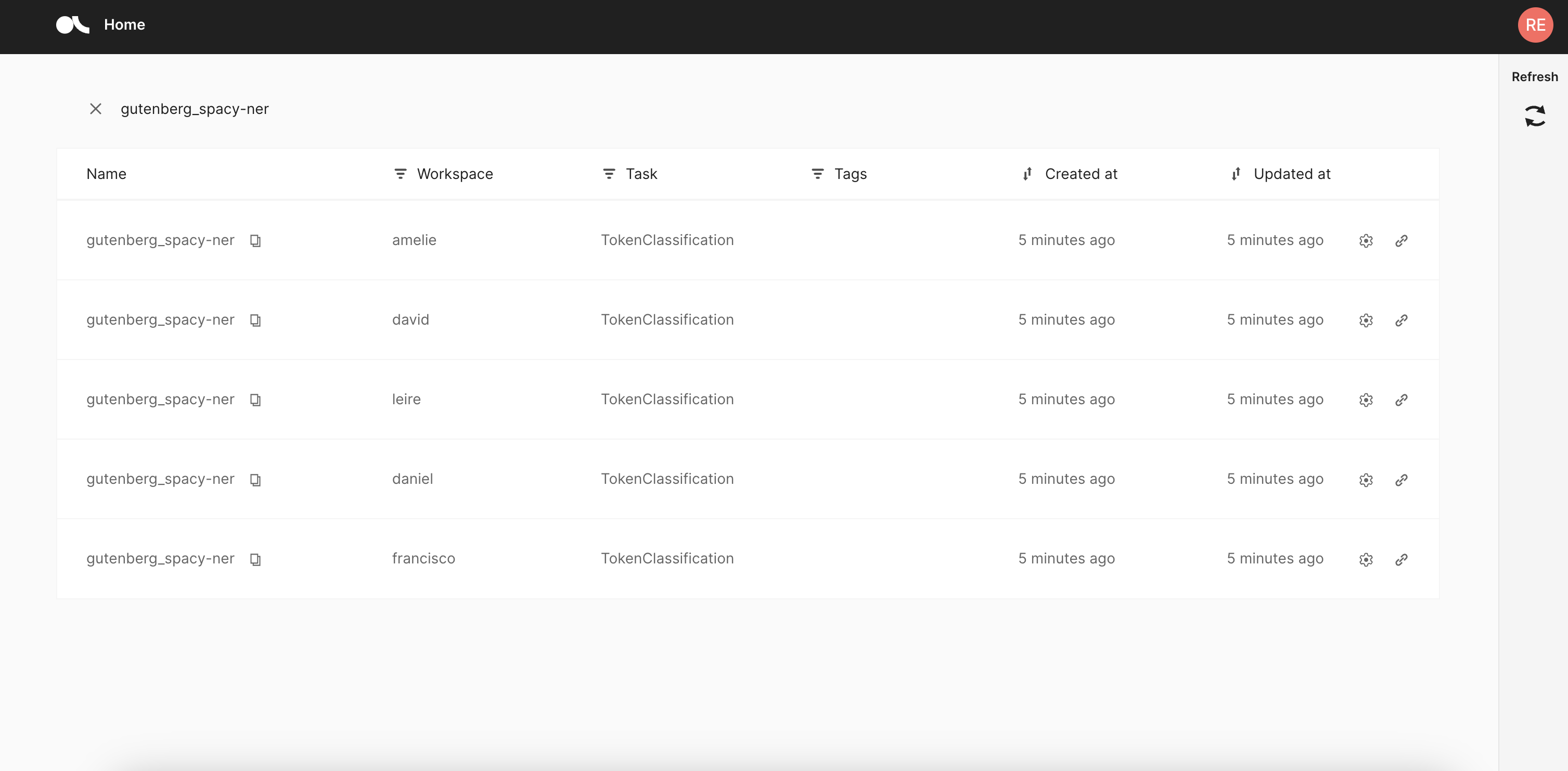 View of the dataset list for an admin user
View of the dataset list for an admin user
**Tip: you can keep the same dataset name for all splits or add a tag to group them easily.
If you don’t want your annotation team to see the splits of their peers, they will need to have the annotator role, as any user with the admin role is able to access all workspaces and datasets. Learn more about user roles and management in this blog post and in our docs.
If you followed this option, your annotation team will find their splits in their personal workspaces. To start annotating they just need to open the dataset, no extra steps needed.
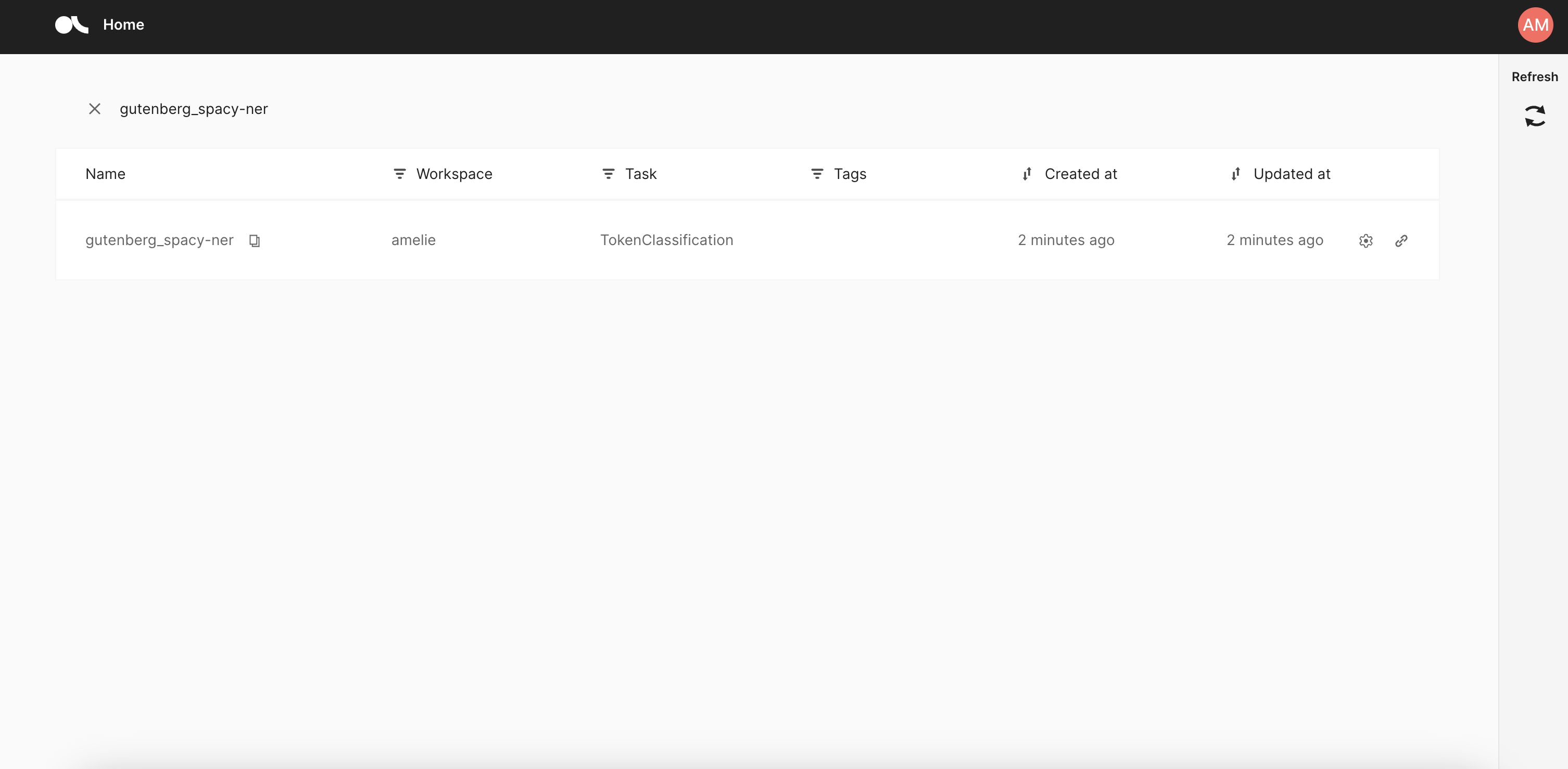 View of the dataset list for the annotator user
View of the dataset list for the annotator user
Summary
We have explored two different ways in which you can use the features in Argilla to divide the workload within your team. In the first solution, we kept a single dataset open to the whole team and used the metadata of the records so that they can filter the dataset and focus on the records assigned to them whenever they need. In the second solution, we made several splits with the records assigned to each team member with the annotator role and logged them as separate datasets in their personal workspaces. That way, we can make sure that they only have access to the records assigned to them, while the admin can oversee all of the splits.
If you want to see a more detailed tutorial with all the code needed to replicate each solution, check out this notebook.


